本次课堂由董小峰老师为我们带来《新一代分布式架构》的课题,主要介绍了如下几个内容:
- 分布式系统发展历程
- 基于 DCN 的分布式架构体系
- 分布式银行系统面临的挑战及实践经验
- 软件技术的发展趋势
笔者针对此次课题,进行了两部分的学习总结:
1、回答问题:简要阐述一个分布式的考试系统或分布式的博客系统是如何从小变大的。由于本次课题的重点在后半部分,此部分笔者写的比较简略。
2、动手实践:使用阿里云服务器+LNMP+WordPress实现了从零搭建一个个人网站,并书写了超详细的搭建过程教程,可查看发布于笔者个人网站的链接:https://ferryxie.com/archives/178
阶段一:单点集中式 web 应用
最开始的系统使用jsp、asp、php等页面语言搭建最简单的业务逻辑,将数据存放在通用关系数据库中,如果有必要还搭建一个WebServer。所有的东西都放在一台服务器上,也就是后面笔者部署的LNMP。这样做的好处就是简单,入门快。
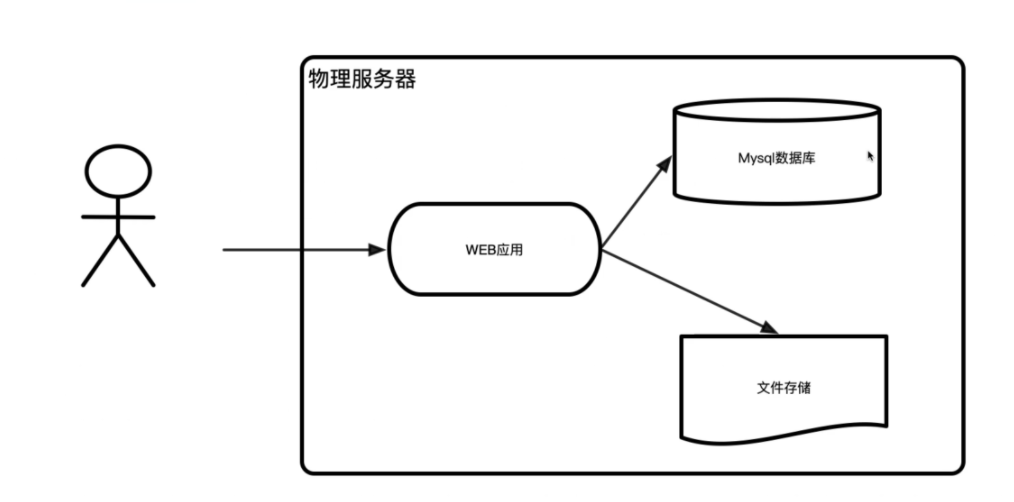
阶段二:WEB应用、文件服务、数据库单独部署
阶段一的单台服务器集成了各种代码,既要负责处理请求参数,又要处理各种逻辑,还要负责连接数据库,最后输出显示…… 可想而知,单台服务器很容易崩掉。所以为了解决资源贫瘠问题,开始使用三台服务器的分布式架构,将WEB 应用、文件服务、数据库都进行单独部署到服务器上。
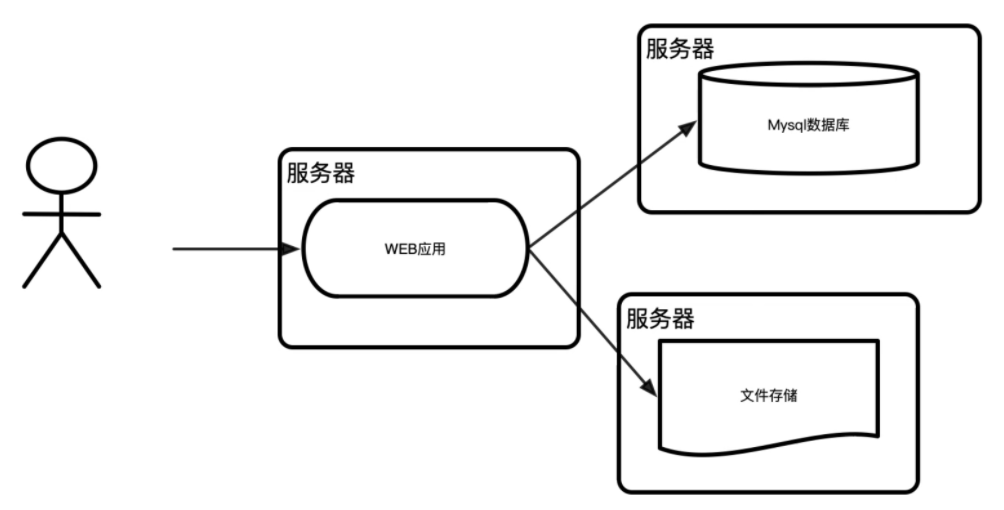
阶段三:引入缓存改善读取性能
随着业务的持续发展,或者是网站关注度逐步提升,请求量逐步变大,往往出现瓶颈的就是磁盘性能。在linux下,用vmstat、iostat等命令,可以看到磁盘的bi、bo、wait、util等值持续高位运行。这个时候就要考虑其他的存储介质,一般使用内存。因为数据存放在内存,访问速度会提高上百倍,并且极大的减少磁盘IO压力。由于内存只能用来保存临时性数据,持久性数据还是需要放到磁盘等持久化介质上。因此,内存可以有多种设计,其中最常见的就是缓存(cache)。
cache引入以后,请求来临的时候,程序先从cache里面取数据,如果数据存在并且有效,就直接返回结果;如果数据不存在,则从数据库里面获取,经过逻辑处理后,先写入到cache,然后再返回给用户数据。这样,就调整内存的大小,以保证有足够的命中率,从而提升服务的响应速度。
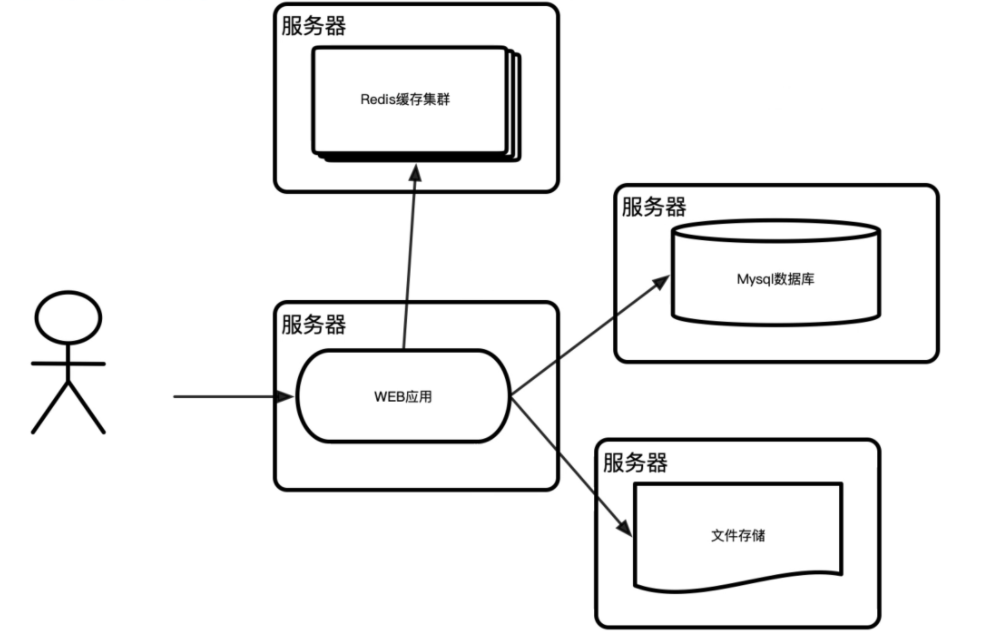
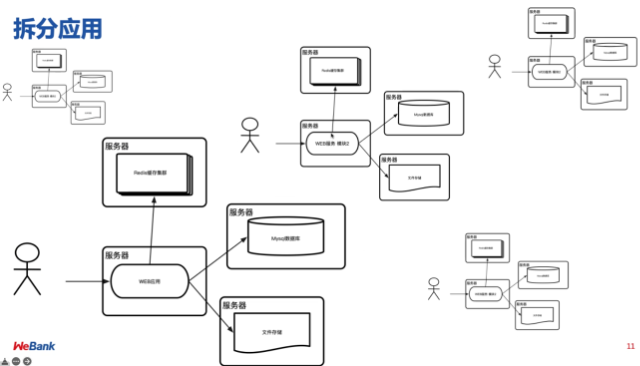
阶段四:拆分应用
但是一个服务器再怎么优化,其处理能力都是有限的。虽然前面介绍的扩容、缓存机制、消息队列等优化方案都是十分有效的,但是当访问量很大时,将一个整体应用拆分为多个应用也不失为一个方案。比如按功能模块及功能模块使用频率拆分。
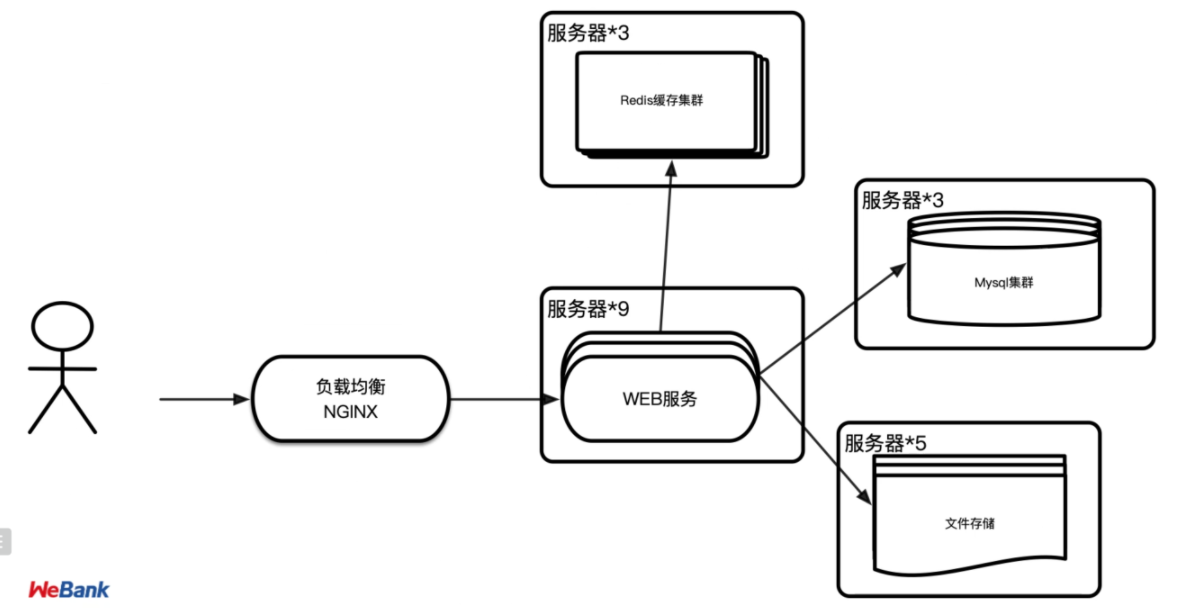
阶段五:引入集群,多机负载均衡,数据多副本
早期网站流量还相对较小,并且业务也比较简单,单台服务器便有可能满足访问需要,但如今一般实际用于生产的系统,几乎都离不开集群部署了。信息系统不论是采用单体架构多副本部署还是微服务架构,不论是为了实现高可用还是为了获得高性能,都需要利用到多台机器来扩展服务能力,希望用户的请求不管连接到哪台机器上,都能得到相同的处理。
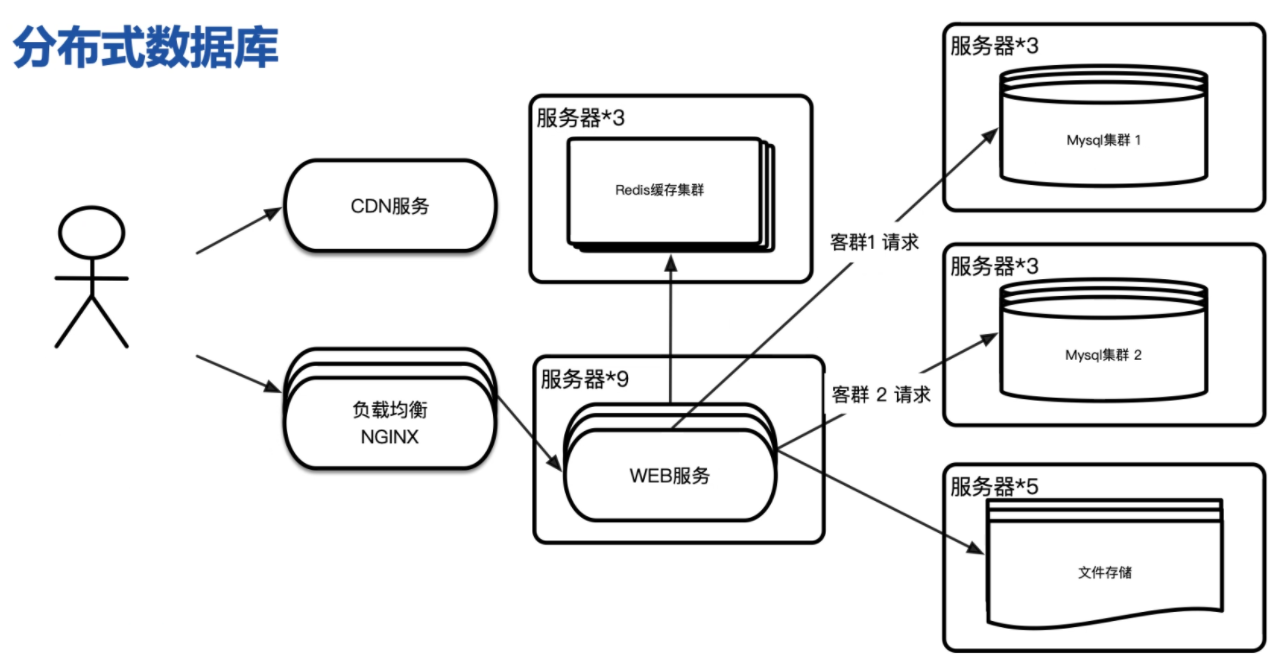
而调度后方的多台机器,以统一的接口对外提供服务,承担此职责的技术组件被称为“负载均衡****”(Load Balancing)****。
阶段六:引入CDN
当下一般互联网应用都包含大量的静态内容,但静态内容以及一些准动态内容又是最耗费带宽的,特别是针对全国甚至全世界的大型网站,如果这些请求都指向主站的服务器的话,不仅是主站服务器受不了,单端口500M左右的带宽也扛不住,所以需要使用CDN服务。
CDN, Content Delivery Network,内容分发网络。简单的说,CDN就是让原本上海的浏览器要访问北京主站内容的请求转而由部署在上海或南京的缓存来受理,这样请求的数据只需经过一跳或有限的几跳就能到达请求端,有效利用带宽并且降低主站压力。
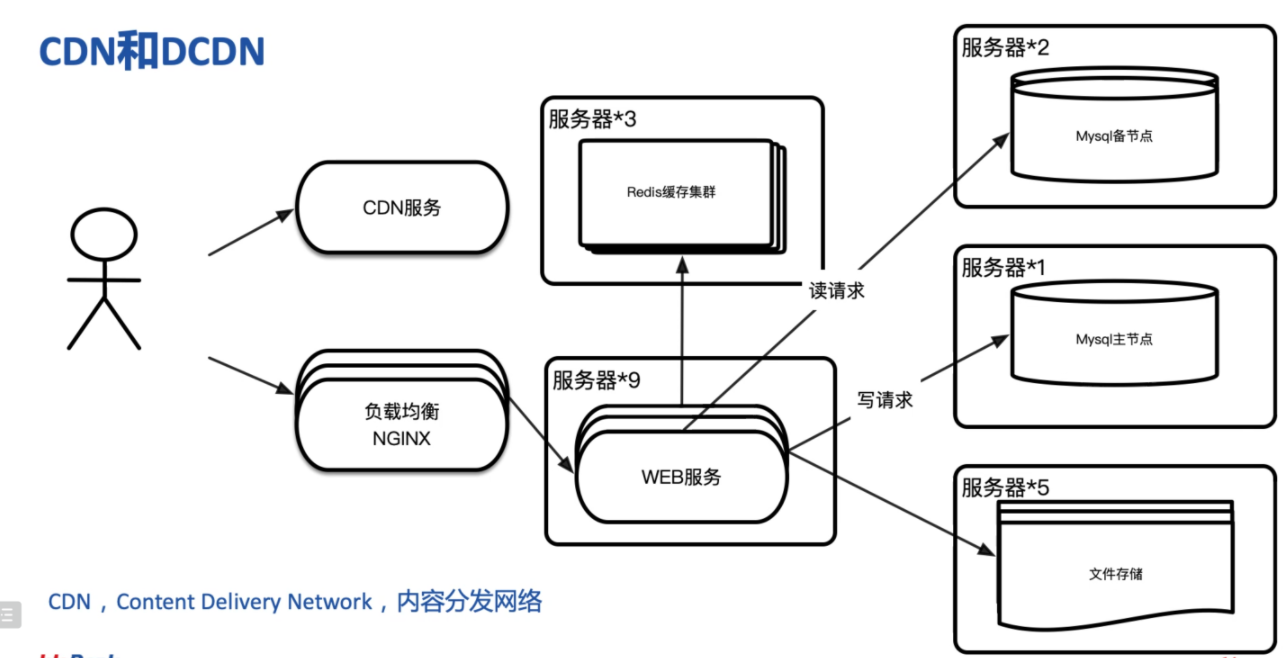
阶段七:分布式数据库
随着数据量的高速增长,需要使用到分布式数据库技术。分布式数据库是指利用高速计算机网络将物理上分散的多个数据存储单元连接起来组成一个逻辑上统一的数据库。分布式数据库的基本思想是将原来集中式数据库中的数据分散存储到多个通过网络连接的数据存储节点上,以获取更大的存储容量和更高的并发访问量。