一、实验目的与要求
- 熟练掌握k-Means方法对手写数字图像进行分类;
- 编写代码,熟悉其画图工具,进行实验,并验证结果;
- 锻炼数学描述能力,提高报告的叙述能力。
二、问题
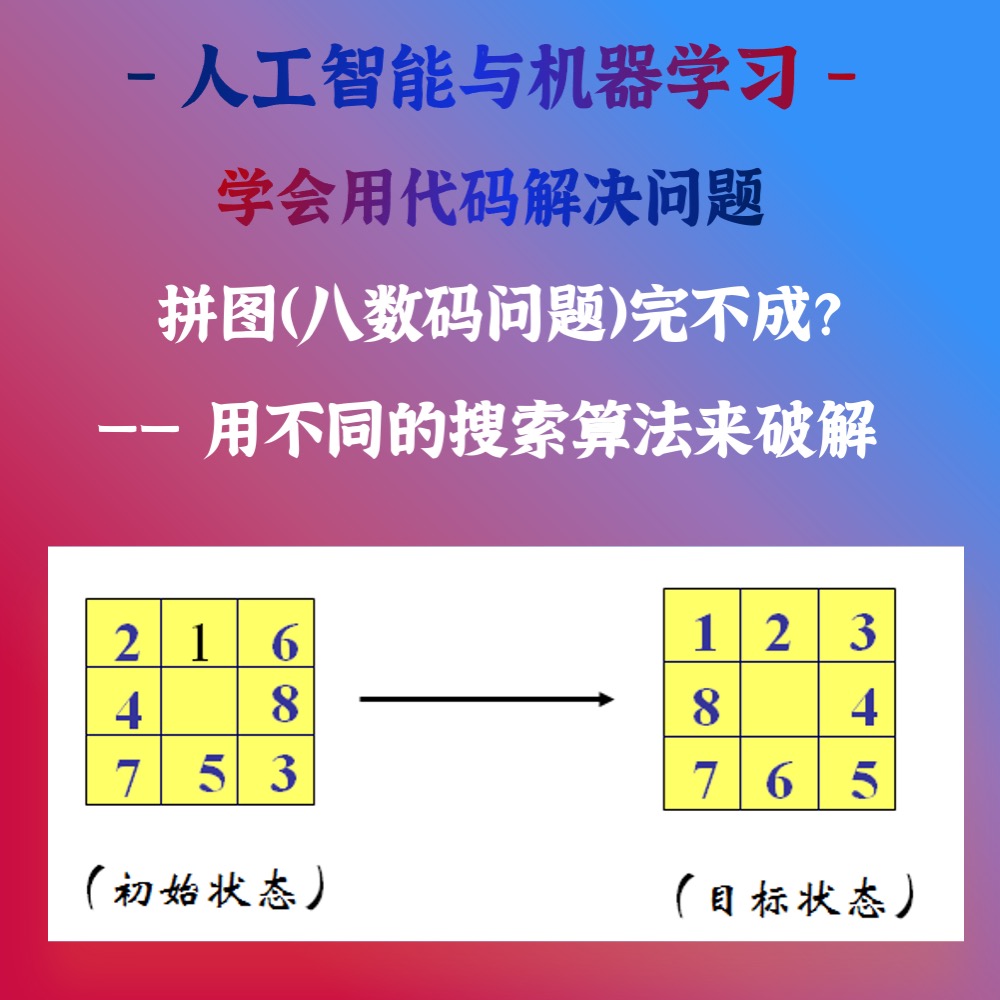
手写数字图像数据分类问题:文件train_images.mat包含大小为28*28的手写数字图像,共60000张;文件train_labels.mat是其对应的数字标签。文件数据的具体读写和数据格式,请参考附件DataRead.m文件。实验要求对手写数字图像进行聚类,并讨论其性能:(MNIST DATABASE下载)
(1) 对train_images.mat的前100张手写数字图像进行聚类,共10类;

文件前100张手写数字图像
(2) 对train_images.mat的前1000张手写数字图像进行聚类,共10类;
(3) 根据实际情况,讨论k-Means能对多少张手写图像进行聚类,性能如何?
三、模型建立及求解
本次实验实现过程的思维逻辑如图1所示:

图1 K-means实验实现过程思维逻辑图
3.1 实验思路
- 实验工具:由于笔者对MATLAB语言不太熟悉,在进行了一些尝试之后,为了更好地完成这次实验,还是决定使用笔者相对熟悉的Python进行实验。
- 实验数据: MNIST数据集是机器学习领域中一个经典数据集,由 60000 个训练样本和 10000 个测试样本组成,每个样本都是一张 28 * 28 像素的灰度手写数字图片。 本次实验使用到MNIST的手写体的图像数据(train_images.mat)和图像数据对应的标签(train_labels.mat)。
- 实验目标:本次实验要求使用K-means算法建立模型,对手写体进行聚类,再对聚类的结果来进行性能对比和分析。
- 实验思路:
- 读取并分析MNIST数据集
- 使用K-means算法对手写体进行聚类
- 使用PCA算法对聚类结果进行二维可视化
- 对聚类结果进行性能分析(聚类时间+准确率)
3.2 模型建立
3.2.1读取MNIST数据集
由于所给的手写体文件是以mat格式来存储的,在Python中需要使用相关的工具库进行导入,这里笔者使用scipy.io中的函数loadmat()来读取mat文件。最终得到的images数据是一个(28,28,60000)的三维数组,labels数据是一个(1,60000)的二维数据。图2展示了导入成功后,其中一张手写体及其标签的灰度像素图片。

3.2.2 使用K-means算法对手写体进行聚类
1. K-means 算法思想
经典 K-means 算法的基本工作流程:首先随机选取 K 个数据作为的聚类的聚类中心,计算各个数据对象到所选出来的各个中心的距离,将数据对象指派到最近的类中;然后计算每个类的均值,循环往复执行,直到满足聚类的收敛条件为止。具体的执行步骤如表1所示:

2. K-means算法的具体实现
- 参数设置
- times:因为K-means算法每次运行的结果都不一致,为了减少极端准确率的影响,所以定义变量times表示算法重复进行的次数(后面在计算精确度时可以对每次运行结果的精确度取平均得到);
- m:表示使用数据集的前m张图片进行聚类;
- k:表示聚类的类别数,这里因为是手写数字0-9,因此把k设置为10;
- num_iters:表示算法迭代的次数,当达到迭代次数的时候,则退出算法;
- 初始化聚类中心,从选择的前m张手写体数据集中随机挑选出k个样本作为质心;
- 计算出每一张手写体图片与聚类中心的距离,挑选出每张手写体图片距离最近的聚类中心,并把聚类中心的下标按顺序储存到数组C中;
- 接着继续更新质心。重新计算质心后,若质心改变,则更新质心,这时候迭代次数num_iters+1。笔者在这里设定当迭代次数达到20时,则退出迭代。
3. 聚类中心对应类团编号的获取
- 通过C_labels列表, 在内部嵌套K个列表list,形成“列表中列表”的数据结构。将K-Means函数得到的K个类团中每个类团的实际labe1进行存储。
- 根据每个类团存储的label数进行计数,把labe1数最多的作为本类团的编号(如:类团[1,2,3,3,3,3,4,4],其中编号出现最多的是“3”,因此3作为本类团的聚类中心)。
- 如果list中label与计数最多的相同的个数有多个,则取第一个label作为本类团的聚类中心(如:类团[1,2,3,3,4,4],其中编号出现最多的是“3”和“4”,因为3排在前面,因此讲3作为本类团的聚类中心)。
4. 正确率计算
利用存储图片对应数字的数组和上一步求得的聚类中心数字可以得到利用K-means算法识别的数字结果,再将其与train_labels(每张图片真正的label)对照并计算识别正确率。(精确度 =正确数/总数)
5. 使用PCA算法对聚类结果进行二维可视化
为了对聚类的效果进行映射到二维平面的可视化,以直观显示出聚类效果的散点图,所以需要将维度为 28×28=784 的手写体图片降到2维。
主成分分析(PCA)是最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等。PCA可以把具有相关性的高维变量合成为线性无关的低维变量,称为主成分,主成分能够尽可能保留原始数据的信息。原理就是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,依次类推。 PCA算法流程如表2所示:

这里,笔者使用Python的sklearn库,调用decomposition.PAC加载PCA进行降维,使用参数n_components指定主成分的个数为2,即降维后数据的纬度为2。封装成display()函数,然后分别对聚类前后的样本进行可视化。
3.3 性能分析
1. 运行环境
MacOS Big Sur + Intel I5 + 16G内存 + Pycharm
2. 复杂度分析
k个聚类中心,m个数据,计算两数据之间二范数的复杂度为O(d),则聚类一次的时间复杂度为O(kmd)。对于dim”*” dim像素的灰度图像,两数据间的欧氏距离的复杂度为3*dim*dim。所以时间复杂度可以写为O(3*dim*dim*km)。重新确定聚类中心所需的时间复杂度为O(dim* dim * m),少于第一步。k-Meams的时间复杂度则为O(dim*dim*km)。
3. 在聚类数k=10的前提下,逐步增加样本数进行对比
a. 当m=100时
首先设置参数,m=100,k=10,times=100,将前100张手写数字图像聚成10类,并且重复运行100次,得到如图3所示的可视化图表。可以看到,100次聚类测试中,聚类的平均正确率为59.50%,最高达到70%,最低为46%,方差为0.002,每次聚类的平均时间为0.051s。


接下来,笔者将探究:在 10 个聚类中心的前提下,随着聚类的样本数的增加,K-means算法的匹配正确率是否会有显著差异。
b.当m=1000时
设置参数,m=1000,k=10,times=100,将前1000张手写数字图像聚成10类,并且重复运行100次,得到如图4所示的可视化图表。可以看到,100次聚类测试中,聚类的平均正确率为54.45%,最高达到62.70%,最低为45.10%,方差为0.001,每次聚类的平均时间为1.392s。

由于篇幅所限,笔者就不在这里详细画出其他情况的正确率折线图。这里随着样本数目不断增多,算法运行时间不断增加,受制于硬件性能,当样本增加到9000时,100次的运行次数已经较难完成了,所以当m≥9000时,本实验的测试次数减少为10次,但10次取平均得到的正确率也可以较好地说明问题了。结果总结如表4所示,可以看到,在10个聚类中心的前提下,随着聚类的样本数的增加,K-means算法的平均正确率都集中在55%-60%,样本量的增加没有带来正确率的显著差异,但是平均运行时间却显著不断增加。

为了探究本次设计的K-Means能对多少张手写图像进行聚类,在k=10的情况,我选取数据集中全部60000张图片进行聚类,如图5所示,可以看到聚类的正确率为58.97%,仍处于55%-60%的区间,运行时间为249.778s。所以本K-Means算法能完成对全部60000张手写图像进行聚类,性能正确率可以达到58.97%。

4. 在样本数m=100的前提下,增加聚类中心k的数量进行对比
接下来,笔者还将探究:在聚类样本数m=100的前提下,随着聚类中心k的增加,K-means算法的匹配正确率是否会有显著差异。
设置参数,m=100,k=15,times=100,将前100张手写数字图像聚成15类,并且重复运行100次,得到如图6所示的可视化图表。可以看到,100次聚类测试中,聚类的平均正确率为67.21%,最高达到79.00%,最低为58.00%,方差为0.002,每次聚类的平均时间为0.067s。可以看到随着聚类中心的增加(从10到15),聚类的平均正确率显著提升,但聚类的平均时间也有所增加。(如前面图2所示,当k=10时,聚类的平均正确率为59.50%,最高达到70%,最低为46%,方差为0.002,每次聚类的平均时间为0.051s。)


5. 使用PCA算法对聚类结果进行可视化
当m=100,k=10时,运行程序,正确率为57%,得到如图7的聚类可视化结果:

图7:m=100,k=10的聚类前(左边)和聚类后(右边)的可视化结果

图 8:m=1000,k=10 的聚类前(左边)和聚类后(右边)的可视化结果
在经过PCA算法的可视化后,可以轻易看出数据集使用K-Means进行聚类并不能有很好的效果。虽然有一部分是因为K-means 是根据28*28来度量距离的,取前两维之后可视化的效果不会特别好。但是其实作为一种无监督的基于距离的聚类算法,K-Means算法虽然易于理解并被广泛运用,但算法并没有完美一说,K-Means时间复杂度较高并且在实际问题中聚类中心的数量和选取在一开始难以精准确认,这都使得K-Means算法的聚类结果并没有表现的很好,仍存在着一些问题。
3.4 存在的问题
- 因为未加入随机重启机制仅运行一次聚类算法,会使得运行结果有很大概率仅为局部最优解而不是全局最优解。所以这种用局部最优解代替全局最优解的方法,虽然能显著降低时间复杂度,但代价是聚类结果对初始聚类中心的选取比较敏感。
- 对于k-Means初始聚类中心的选择方法主要有两种。一,选择批次距离尽可能远的k个点;二,选用层次聚类或者Canopy算法进行初始聚类,然后利用这些类的中心点作为k-Means算法初始类团的中心点。
- 在本次实验中,关于K-means算法,还存在正确率待提高的问题,若还有时间笔者会进一步对上述的优化算法进行实验验证。
四、小结(可含个人心得体会)
4.1 实验小结
- 本次实验,笔者在完成了K-means算法后,根据对不同聚类样本数和聚类中心数进行测试和对比,从而分析算法的性能,最后还扩展实现了PCA算法对聚类结果进行可视化对比。
- 随着聚类样本数的增加(m = 100,1000,3000,5000,7000,9000,11000),聚类的平均正确率并没有显著差异。这可能是因为随着聚类样本数的增加,在10个聚类中心的前提下,随着带来的错误匹配概率也增加,因此聚类样本数增加并不意味着聚类结果正确率更高。
- 随着聚类中心数的增加(k=10,15),聚类的平均正确率有明显提高,且迭代次数降低,收敛变快,这可能是因为聚类中心数的增加提高了程序可容错性,不过也导致了平均聚类时间有一些增加。
- 经过PCA算法的可视化后,可以轻易看出数据集使用K-Means进行聚类并不能有很好的效果,期待之后使用KNN等算法进一步对手写体数据进行实验对比。
4.2 个人体会
- 本次实验,笔者在刚开始尝试使用Matlab完成实验,但后发现自己确实不太会用matlab,比较难将完成度做得好一些,然后转向用python来进行实现。在K-means算法和PCA算法的具体实现和逻辑连接上,笔者也花费了挺多时间来思考代码的整体框架,各种debug,最后还算是比较成功地完成了任务,收获颇丰。
- 在测试的过程中,当样本量增加的时候,在跑数据的过程中,笔者还同步写实验报告“这里尽管样本数目不断增多,但为了数据的对比准确度,笔者不惜等待时间,仍然对每种情况都进行了100次测试。”但数据实在跑了很久都没有完成…最后我妥协了,当m≥9000时,笔者将测试次数减少为10次。现在想想,因其他杂事众多,生活中不能按照自己理想主义般的方式去探索世界,而是向现实妥协真不是很好受…
代码附录
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as scio
import random
import time
from sklearn.decomposition import PCA
def display(X, C):
color = ['blue', 'red', 'green', 'orange', 'pink', 'gray', 'olive', 'cyan', 'pink', 'purple', 'brown']
pca = PCA(n_components=2)
tmp_data = X
# X_2d = pca.components_.T
pca.fit(tmp_data)
C_list = []
for c_list in C:
tmp_c = []
for ci in c_list:
tmp_c.append(ci.ravel())
C_list.append(tmp_c)
X_new = []
for C in C_list:
X_new.append(pca.transform(C))
# show src_data
for i in range(len(X_new)):
for x in X_new[i]:
plt.scatter(x[0], x[1], c=color[labels[0][i]], marker='o', s=15)
plt.show()
# show dst_data
for i in range(len(X_new)):
for x in X_new[i]:
plt.scatter(x[0], x[1], c=color[i], marker='o', s=15)
plt.show()
if __name__ == '__main__':
images_file = '/Users/fubo/Desktop/train_images.mat'
labels_file = '/Users/fubo/Desktop/train_labels.mat'
images = scio.loadmat(images_file)
images = images['train_images'] # size:(28,28,60000)
labels = scio.loadmat(labels_file)
labels = labels['train_labels'] # size:(1,60000)
total_time = 0
total_rate = 0
times = 5 # 重复进行的次数
rate_set = []
for j in range(times):
counter = 1
start = time.time()
m = 1000 # 前m张图片
k = 10 # 类别数
index = [i for i in range(m)]
miu = [] # 所有质心
X = []
for i in range(m):
xi = images[:, :, i]
X.append(xi.ravel())
X = np.array(X)
init_index = random.sample(index, k)
for i in init_index: # 随机选择样本作为质心
miu.append(images[:, :, i])
num_iters = 0 #迭代次数
while True:
C = [] # 所有的类
C_labels = []
for i in range(k):
Ci = [] # 每一类
Ci_labels = []
C.append(Ci)
C_labels.append(Ci_labels)
# 将样本划入最近的质心对应的类
for i in range(m):
xi = images[:, :, i]
# F2范数计算距离,即欧几里得距离
# 每个点都看看和哪一个质心距离最近
d = [np.linalg.norm(xi - miu[j]) for j in range(k)]
min_i = d.index(min(d)) # 质心距离最小的下标
# 这个质心吸收了这个点
C[min_i].append(xi)
C_labels[min_i].append(labels[0, i])
# 更新质心
update = False
for i in range(k):
xi = np.zeros((28, 28), dtype='float32')
# 重新计算质心
for xj in C[i]:
xi += xj
xi /= len(C[i])
# 质心改变,则更新
if not (miu[i] == xi).all():
update = True
miu[i] = xi
# 已经迭代了20次
num_iters += 1
if num_iters == 20:
break
if not update:
break
correct = 0
# 精度计算
# C_labels 中有10个 list
# print(len(C_labels))
# 每个list中有正确的label,选择最多的label作为该类的label,计算该类label有多少个
c_belong = 1
for label_list in C_labels:
correct_each = 0
label = max(label_list, key=label_list.count) # 计数 拿最多
print("%d---%d" % (c_belong, label))
c_belong += 1
for t in label_list:
# 计数list中label与计数最多的相同的个数
if t == label:
correct_each += 1
correct += correct_each
print('try %d times get accurate %.2f%%' % (num_iters, 100 * correct / m))
# print('___________________')
end = time.time()
total_time += end - start
print('%.3fs ' % (end - start), end="")
# 计算聚类精度
correct = 0
for label_list in C_labels:
correct_each = 0
label = max(label_list, key=label_list.count)
for t in label_list:
if t == label:
correct_each += 1
correct += correct_each
rate_set.append(correct / m)
print('%.2f%%' % (100 * correct / m))
#total_rate += correct / m
print(rate_set)
max_indx = np.max(rate_set) # max value index
min_indx = np.min(rate_set) # min value index
mean_indx = np.mean(rate_set) # mean
var_indx = np.var(rate_set) #var
print(max_indx, min_indx, mean_indx,var_indx)
plt.figure()
plt.plot(np.arange(times) , rate_set, color="black",lw=1.5)
plt.grid(True)
plt.title("K-means Accuracy ")
plt.xlabel("Number of times")
plt.ylabel("Accuracy")
plt.show()
display(X, C)
print()
print('前%d张' % m)
print('%.3fs ' % (total_time / times), end="")
# print('%.2f%%' % (100 * total_rate / times))