问题描述
今年笔者参与了一个法律与市场相关的科研项目,在团队中,笔者主要负责数据抓取、处理和分析。在上一篇文章「【Python爬虫——批量爬取北大法宝网(pkulaw)的法律判决书】看似简单的任务为何如此麻烦?Selenium破解滑块验证|Xpath解析HTML|Re正则表达式文本分析」中,笔者写到还有一些问题尚未处理,这个项目战线实在太久了,是时候一鼓作气将其完全解决掉了。
自动化下载北大法宝网上的4000篇法律判决书
问题分析与突破口
在上一篇文章讲到,由于科研的数据需求,需要下载北大法宝网的4000多篇HTML格式的法律判决书。笔者是用爬虫爬取,结果律协的账号都被封掉了…所以想着曲线救国,能不能直接联系官方经理帮忙下载,正当笔者为自己的「另辟蹊径」自鸣得意时,催促沟通了快一两周的客户经理却给了这么一个回复,这几万块我还是麻烦我自己吧……

按照官方说法,这种重复性工作真的是笔者最讨厌做的事情,没有之一,又迫于责任不能中途放弃,只能接受了。已经让老师在律协多借了两个账号,准备每天手动枯燥无味地点击几百次,点击一周多来完成第一步的数据下载。
手动下载了两天,实在受不了了这毫无意义的点击下载动作,痛苦推动改变,笔者开始搜索,寻求解决方案。终于有了两个突破口:
- 由于之前解决了滑块验证的问题,编程使用selenium实现自动化下载不是很困难;
- 对于每天限制下载200篇的问题,笔者发现学校已经购买了这个数据库,使用校园网登录后没有下载限制。
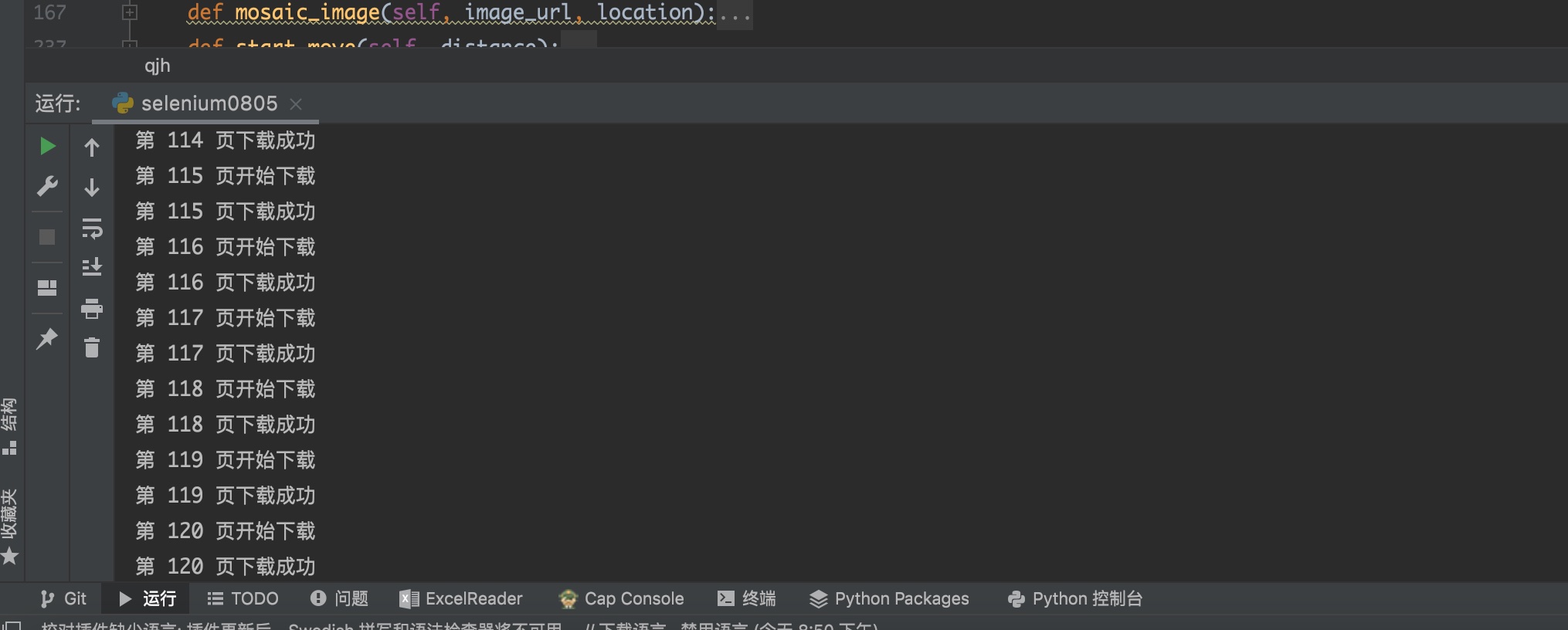
有了这两个突破口,问题看似就很好解决了,接下来就开始使用selenium来自动化帮忙重复点击,解放双手。最终的效果如下,每页下载成功后都会输出提示。(笔者自我提醒:使用代码 selenium0805.py)
代码实现
在开始之前,有以下点需要注意:
(1)这里主要使用的是python中selenium这个自动化工具,关于这个库的基础知识可以参考 selenium用法详解【从入门到实战】【Python爬虫】【4万字】这篇文章,讲的很详细清晰。
(2)笔者的程序都是使用Xpath定位。如果你要修改代码,定位到别的元素,有个很好用的技巧,可以在浏览器中按F12打开开发者模式,在要寻找的元素位置上右键点击检查,定位到元素的HTML位置,然后在中右键复制XPath,这样可以很快就找到元素的位置,再用selenium的driver.find_element_by_xpath()来完成页面定位

(3)Todo 可能是由于谷歌浏览器驱动版本的问题,笔者先前使用滑块是百分百破解成功的,但最近chrome浏览器自动更新后,滑块破解有时候会失败。导致这个程序说是「自动化」但其实下载了几十遍后会因为滑块破解失败了而中断,所以这里建议最好不要使用最新版本的谷歌浏览器。(谷歌浏览器会自动更新,升级后很难在保存数据的情况下降级)
接下来开始展示完整的步骤:
第一步:配置chromedriver驱动
下载对应版本的谷歌驱动,并配置好路径。每次通过self.allurl修改要爬取的页面,通过url修改要爬取的页面。
def __init__(self):
chrome_option = webdriver.ChromeOptions()
# chrome_option.add_argument('--headless') # 设置chrome浏览器无界面模式,使用个人账号时可以使用,使用IP登录时不能使用
# chromedriver不同版本下载地址:https://chromedriver.storage.googleapis.com/index.html
self.driver = webdriver.Chrome(executable_path=r"/Users/fubo/Desktop/Git/spider_new/chromedriver",
chrome_options=chrome_option)
self.driver.set_window_size(1440, 900)
# 在这里修改要爬取的页面
self.allurl = [int(i) for i in range(197, 200)]
# 核心函数
def core(self):
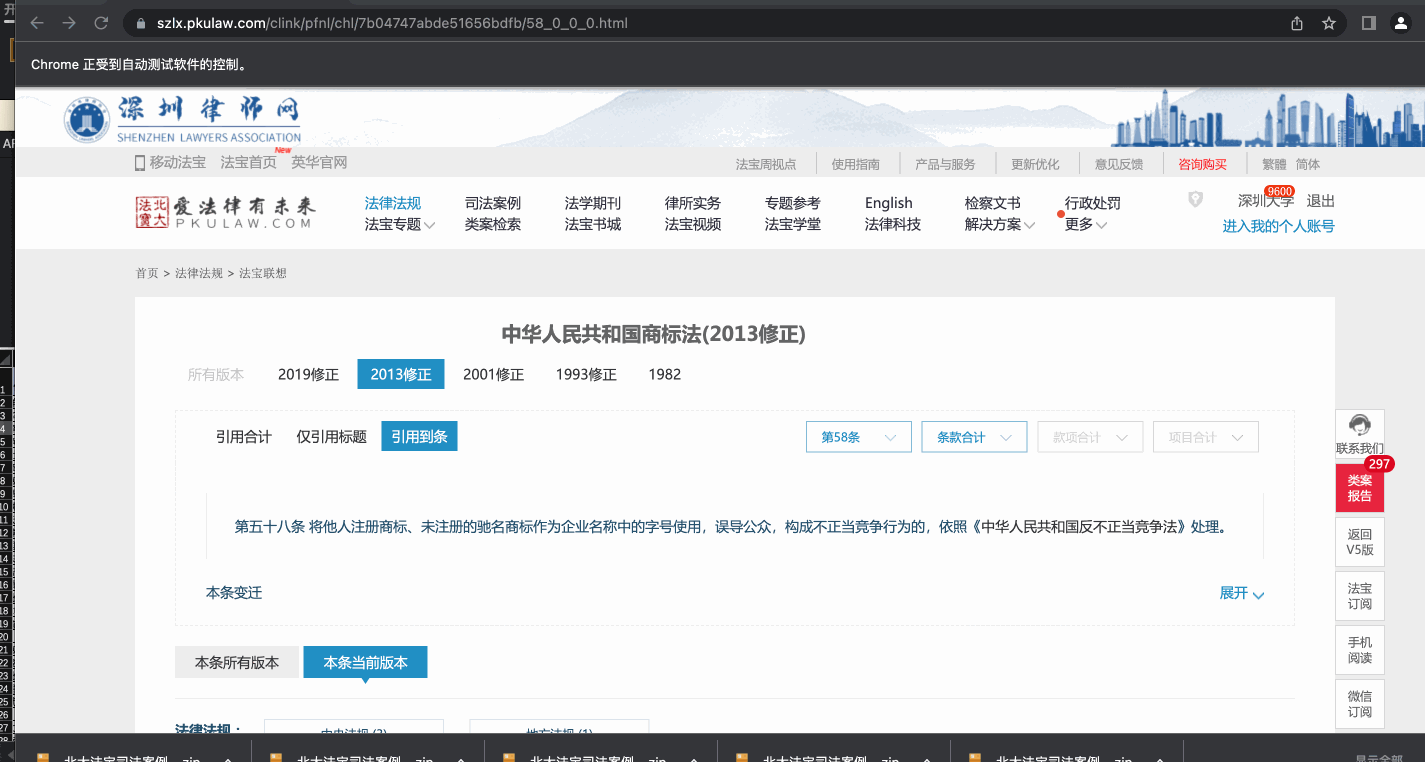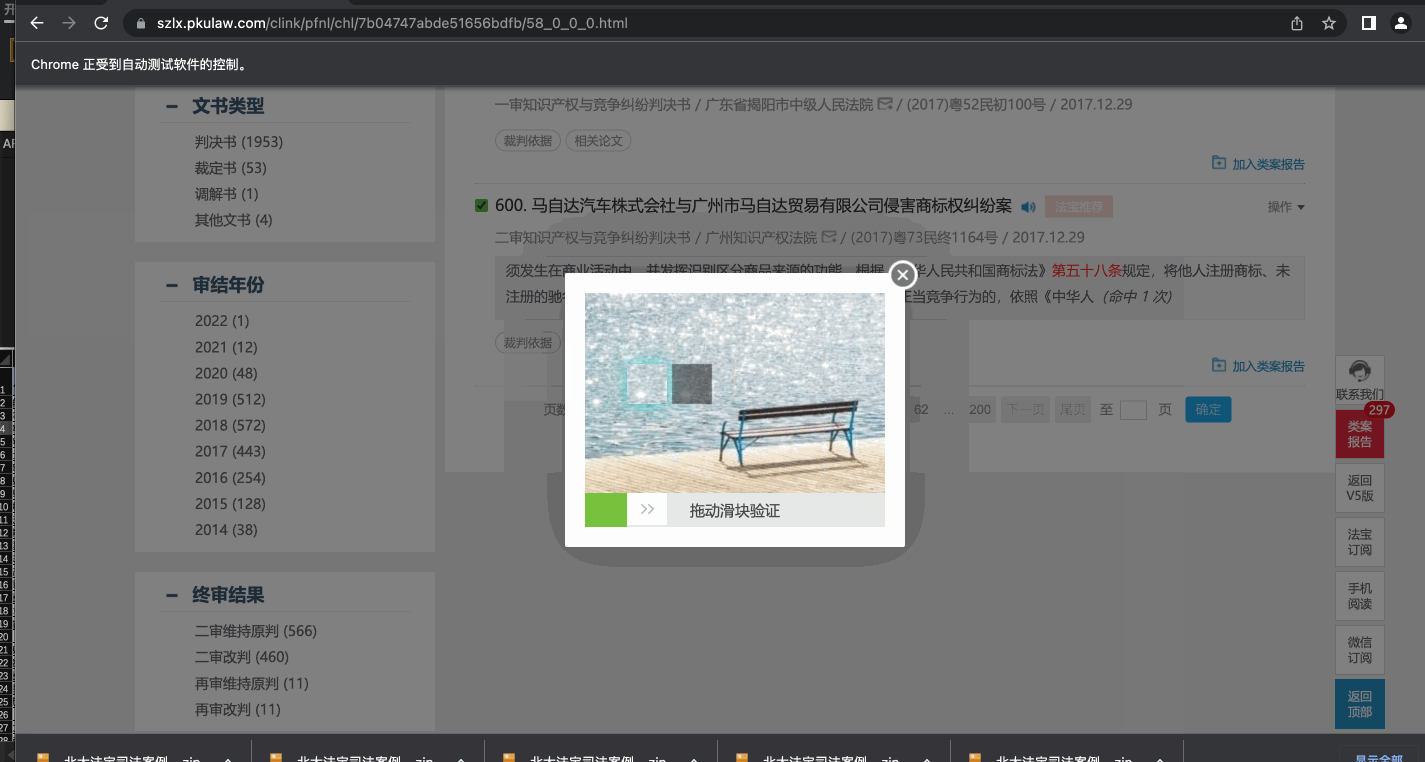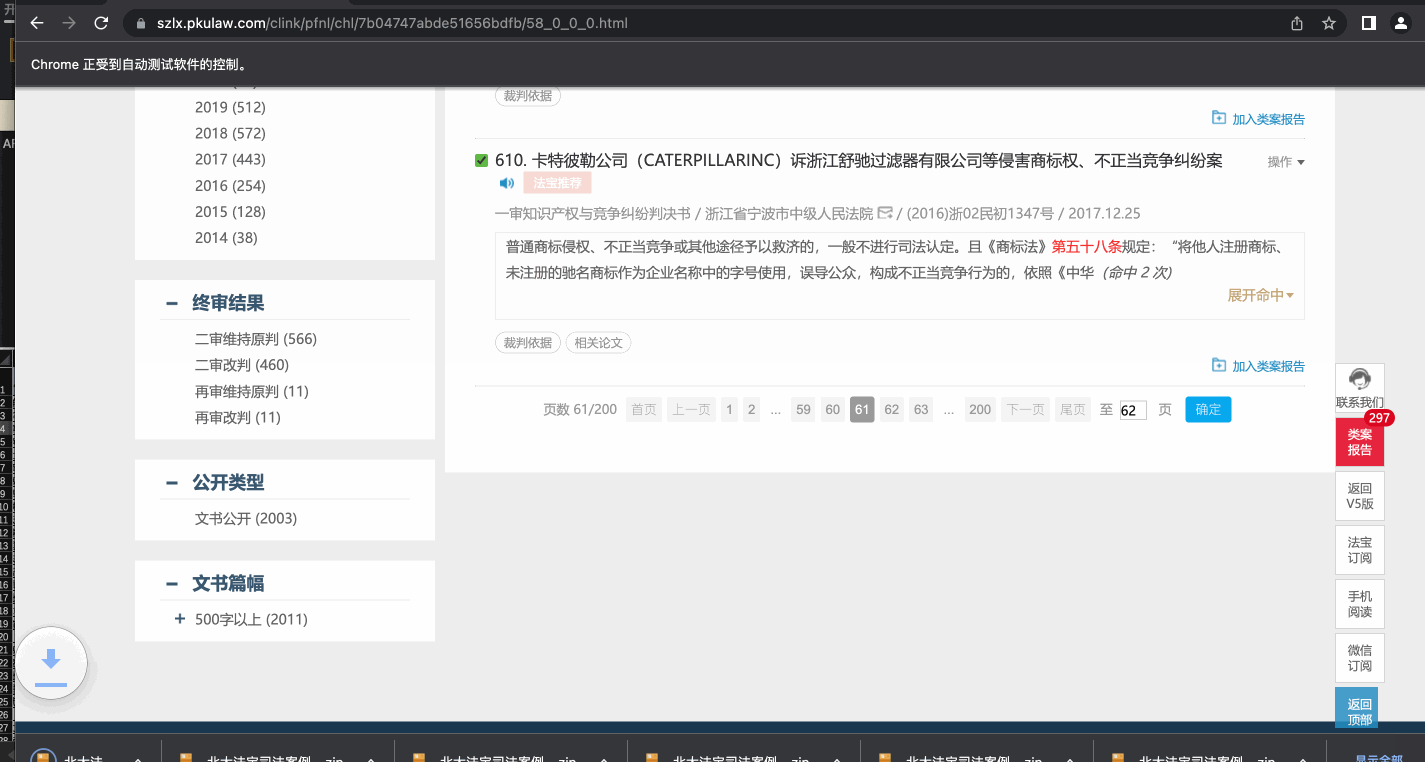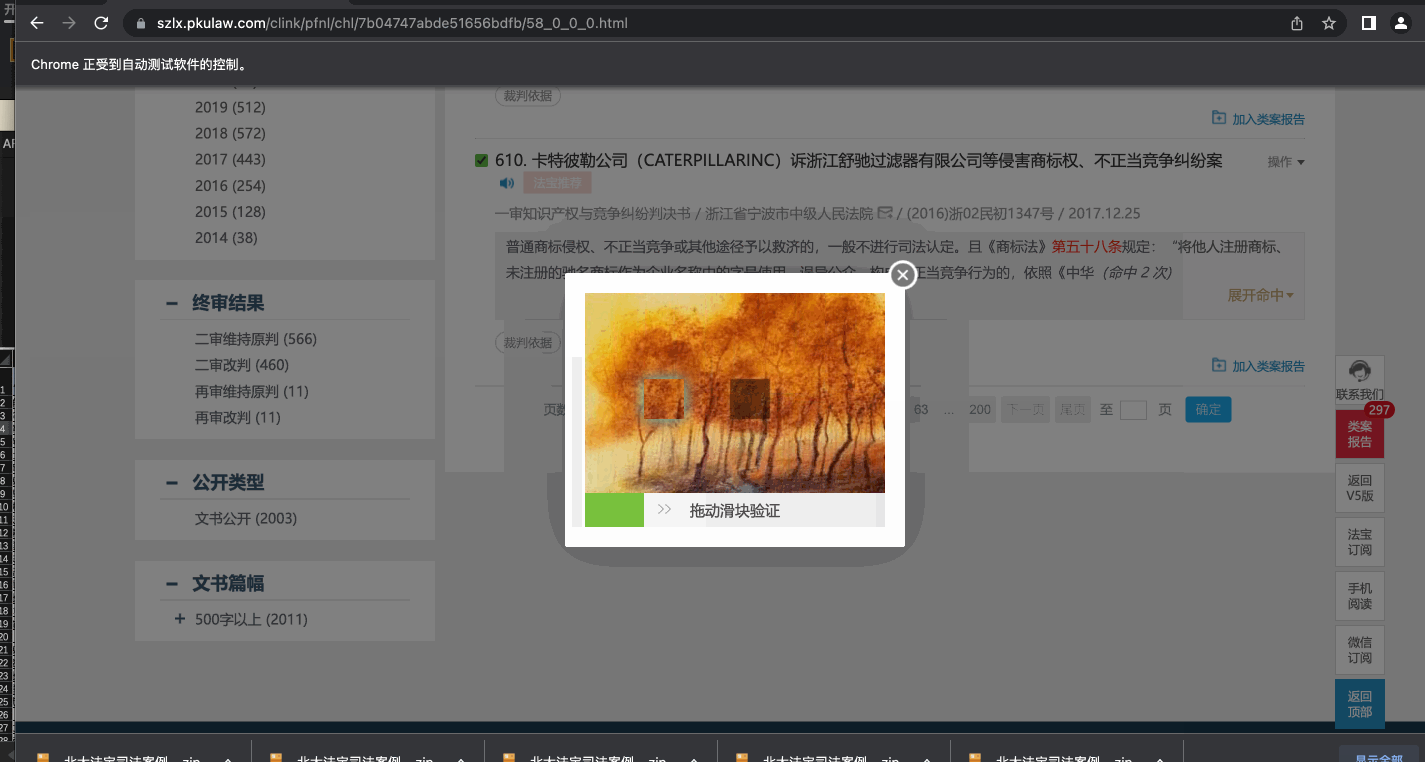
url = "https://szlx.pkulaw.com/clink/pfnl/chl/7b04747abde51656bdfb/58_0_0_0.html" # 2013
# url = "https://szlx.pkulaw.com/clink/pfnl/chl/937235cafaf2a66fbdfb/58_0_0_0.html" # 2019
self.driver.get(url)
第二步:模拟登录。如果使用官方账号登录,则需要模拟输入账号密码;如果使用的是IP登录,则不需要登录,可将这个部分注释掉。将账号密码替换成自己的。
# 模拟登录,找到登录框的位置,密码保密!!
zhanghao = WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.XPATH, '//*[@id="email-phone"]')))
# 输入账号
# zhanghao.send_keys('xx') # 账号
mima = WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.XPATH, '//*[@id="password"]')))
# 输入密码
mima.send_keys('xx') # 密码
time.sleep(1) # 等待加载
# 点击登录
denglu = WebDriverWait(self.driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//a[@class="btn-submit"]')))
denglu.click()
time.sleep(2) # 等待加载
第三步:由于要下载的页面是法宝推荐,登录之后还有几步跳转。
# 进入法宝推荐界面
tuijian = WebDriverWait(self.driver, 10).until(EC.element_to_be_clickable((By.XPATH, '//a[@title="法宝推荐 (2011)"]'))) # 2019年:0803-数据2103 0806-数据2109;2013年:0806-数据2011
tuijian.click()
time.sleep(1)
#滑动到底部
js_button = 'document.documentElement.scrollTop=100000'
self.driver.execute_script(js_button)
time.sleep(1) # 等待加载
#点击更多
more = WebDriverWait(self.driver, 10).until(EC.element_to_be_clickable((By.XPATH, '//a[i[@class="c-icon c-eye"]]')))
self.driver.execute_script("arguments[0].click();", more)
time.sleep(1)
第四步:按照allurl的页面范围设置开始翻页。每次跳转需要先在翻页框中输入页码,再点击确定。
# 往方框里输入页码
input = WebDriverWait(self.driver, 100).until(EC.presence_of_element_located((By.XPATH, '//input[@name="jumpToNum"]')))
input.send_keys(i)
time.sleep(1)
# 点击确定按钮跳转,需要使用js增强,防止页面丢失
button = WebDriverWait(self.driver, 100).until(EC.element_to_be_clickable((By.XPATH, '//a[@class="jumpBtn"]')))
self.driver.execute_script("arguments[0].click();", button)
time.sleep(1) # 等待加载
第五步:从page21开始,每次翻页都需要滑块验证,调用已经编写好的验证函数(放在后面完整代码部门)。由于滑块不是百分百成功,所以多次尝试,如果尝试五次都没有成功,就是破解失败了。(Todo但这种写法效率很低,需要优化以使得运行速度更快。)
for l in range(1,5):
try:
cut_image_url, cut_location = self.get_image_url('//div[@class="cut_bg"]')
cut_image = self.mosaic_image(cut_image_url, cut_location)
cut_image.save("cut.jpg")
self.driver.execute_script(
"var x=document.getElementsByClassName('xy_img_bord')[0];"
"x.style.display='block';")
cut_fullimage_url = self.get_move_url('//div[@class="xy_img_bord"]')
resq = base64.b64decode(cut_fullimage_url[22::])
file1 = open('2.jpg', 'wb')
file1.write(resq)
file1.close()
res = self.FindPic("cut.jpg", "2.jpg")
res = res[3][0] # x坐标
self.start_move(res)
if self.driver.find_element_by_xpath('//*[@id="bb5"]')==None: #如果没有了滑块的页面,就说明验证成功,可以跳出循环
break
except:
time.sleep(2)
continue
第六步:点击页面全选,批量下载,选择html格式,确定。
# 第一步:找到全选框,点击
quanxuan = WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.XPATH, '//*[@type="checkbox" and @id="choose-all"]')))
self.driver.execute_script("arguments[0].click();", quanxuan) #这里总报错,使用js增强工具解决了问题
# 第二步:点击批量下载
qxxz = WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.XPATH, '//a[@class="down-all"]')))
self.driver.execute_script("arguments[0].click();", qxxz)
# 第三步:选择html格式
xzhtml = WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.XPATH, '//input[@name="batchDownload" and @id = "tool-hyper"]')))
self.driver.execute_script("arguments[0].click();", xzhtml)
# 第四步:点击确定
djqd = WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((By.XPATH, '//a[@id="batchDownload"]')))
self.driver.execute_script("arguments[0].click();", djqd)
这样就写完了这个批量下载的程序,完整代码如下:
文件合并
笔者一晚上下载了400多个页面,拿到了4000多篇HTML文本。虽然由于程序仍不完善,中间中断了好几次,每次都是手动更新要下载的页码,然后重新运行程序。
突然有点复杂的感觉,好像从写程序到改这烦人的中断bug,再到中断重新运行,这些时间加起来好像够笔者手动点击下载完成了…如果从达成目的的角度,似乎我被「工具绑架」了,很不划算啊。但好歹对selenium操作更加熟悉了(自我安慰中…
下载完后,选中这些压缩包,右键选择用「解压缩软件」打开,这样就只是解压到当前文件夹,不会逐个打开文件夹(千万注意:不要直接双击打开,这样会同时打开几百个文件夹,电脑直接崩了…)。
下一步是将几百个文件夹下的html文件合并到一个文件夹,以用来后续做遍历处理。刚开始还以为要用python写个合并脚本,后面想到其实很简单,用finder就可以操作了,在所解压的文件夹中搜索每个html都包含的字段FBM-,稍等一会,全部找到后, 全选并复制到一个新的文件夹就完成合并了。
最后得到了想要的两个文件夹Html:2013年和2019年商标法的判决书文本。(Todo但其中2019年的html文本按道理应该超过2000个才对,虽然已经严格检查了每次下载的页面,暂且不能检查出漏了哪几个案例….)
(file:html_2013,html_2019,html_2019.zip,html_2013.zip)
对HTML的清洗
拿到了所有HTML文本后,笔者将在上次所获取字段基础上按照需求再解析更多字段,包括:(file:test0726.py)
1、案号。之前有些提取出来的结果是“法宝订阅”这个词,笔者重新看了HTML的xpath,发现案号所在的列表不一样,多加了几层判断,进行解决。
# 案号 case_no
try:
#/html/body/div/div[3]/div[1]/ul/li[2]
case_no = e.xpath("//div[@class='fields']/ul[1]//li//@title")[1]
if case_no == '法宝订阅':
case_no = e.xpath("//div[@class='fields']/ul[1]//li//@title")[2]
if case_no == '法宝订阅':
case_no = e.xpath("//div[@class='fields']/ul[1]//li//@title")[3]
except:
continue
2、受理费金额提取。由于此字段目前无较多规律,将就方案为:用正则提取数字相关的金额,后期再人工确定金额的负担方。由于段落中还可能出现数字,但这些数字不表示金额,所以没法单纯通过\d+\.?\d*判断。这里金额出现的情况有太多种情况了,笔者目前通过下面语句判断。【Todo写到这里,发现其实前后两个条件可以只要一个条件,后面的[元|万]其实效率很低,可以在前面的这个条件多找全条件。
shouli_fee_all = re.compile(r"(?<=[负担|承担|费|费用|计|共计|开支|支出|人民币])(\d+\.?\d*)[元|万]", re.S).findall(case_result)
3、裁判结果,原告是胜诉or败诉。这个原文本无明确说明,还是要人工确定。
4、当事人字段。由于判决书中的主体格式太多,上次的提取效果并不好,需要笔者继续进行完善。笔者原先的判断规则以为只有6种情况,但今晚通过看瞎眼般的对比,发现这里不仅名称多样,而且各种括号、冒号的中英文格式不一样,有无空格、冒号等符号也不一样,所以使用之前的正则提取当然结果不好。比如:
"原告:"
"上诉人(原审原告)"
"上诉人(原审原告):"
"上诉人(原审被告):"
"起诉人:"
"上诉人(一审被告):"
"上诉人(一审被告):"
"上诉人(一审被告、反诉原告):"
"上诉人(一审原告(反诉被告)):"
"上诉人(一审原告):"
...
所以这一次通过符号进行切割,获取一个list,再将切错的地方再连接起来,并进行初步的清洗。加上code法宝码和word当事人完整文本这两个变量,重新成一张subject表。
word = word.replace("[\'\\r\\n\\r\\n \',", '').replace("\\u3000\\u3000", '')
word_list = []
word_list = word.split('\',')
word_list_true = word_list
for i in range(0, len(word_list)):
try:
if word_list[i] in (
" \'上诉人(一审被告):", " \'上诉人(一审被告):", " \'上诉人(一审被告):", " \'上诉人(一审原告)", " \'上诉人(一审原告):", " \'上诉人(原审被告)",
" \'上诉人(原审被告):", " \'上诉人(原审被告):", " \'上诉人(原审被告):", " \'上诉人(原审被告):", " \'上诉人(原审原告)", " \'上诉人(原审原告)",
" \'上诉人(原审原告):", " \'上诉人(原审原告):", " \'上诉人(原审原告):", " \'申请人", " \'申请人:", " \'原告", " \'原告(反诉被告):",
" \'原告:", " \'原告:", " \'原告: ", " \'再审申请人(一审被告、二审被上诉人):", " \'再审申请人(一审被告、二审上诉人):",
" \'再审申请人(一审原告、二审上诉人):"):
word_list_true[i] = (word_list[i] + word_list[i + 1]).replace(" \'", '')
word_list_true.remove(word_list[i + 1])
if word_list_true[i] in (" \'当事人"):
word_list_true.remove(" \'当事人")
if word_list_true[i] in (" \'"):
word_list_true.remove(" \'")
except:
continue
word_list_true.insert(0,code)
word_list_true.insert(1,word)
结果基本都提取出来,当事人的字段基本都有,笔者本来是想按照e.g. {被告:xx,法定代表人:xx,委托代理人:xx}的字典格式清洗出来的,但是发现提取出来的表格
(1)每个判决书涉及的主体数量不一样,如何组织?
(2)由于判决书类型不一样,很多字段没有对齐,比如有几十个判决书是优秀案例之类的,数据字段基本对不上的,这就阻止了通过list的元素位置进行提取的思路;
(3)本可以按照关键词进行提取,比如出现“原告(或类似)”,就判断下一个元素是否包含“法定代表人(或类似)”,再判断下一个元素是包含“委托代理人(或类似)”还是包含“被告(或类似)”,这样的方式来提取,但还是因为一是这些代表主体的名词情况太多,需先整理所有情况,再编程,很花时间;二是目前的分割没有完全对齐,增加了判断复杂性;
总之,要完整提取出来,第一步:回归文本列举所有情况;第二步:编程N个判断条件进行分析…这做是可以做,也没有很难,就是巨花时间….
结果提取出来后(file:2013_all_0811_2.csv,2013_subject_0810_1.csv,2019_all_0811_2.csv,2019_subject_0810_1.csv),将2019html和2013html进行合并,接着直接对excel进行初步的清洗。
- 第一步:删除csv的溢出字段,这些字段跟需要的subject字段不相关,直接删除(以2013年数据为例)

- 第二步,去重。删除year、code、title、case_no都相同的字段(这四个字段的组合可以判定唯一性),这些可确定是重复项
所以这一步通过excel的条件格式标注重复项,然后通过法宝码和标题列的条件去除重复。即使下载过程中严格控制住页面了,还是有100多个重复?应该跟法宝的数据库有关:可能是因为法宝的更新是实时的,爬取的过程中法宝刚好更新了,造成了根据页面下载时重复了。但由于按照检查结果2019年的判决书其实有4000多个,但是法宝数据库说明只公开了2000多个,但其实因为只能翻200页,所以其实只公开了2000+个中的2000个,可以从这个原因来解释数据缺失的问题,应该对大结果影响不大。

剩下的可能重复的都进行了标红:

这里需要注意几个数据完整性的问题:
- 4000多案例中,只有2000多公开,确定是因为案件本身法院就没有公开(跟法宝确定过)。比如有如下不公开的原因:
为此,《规定》中明确了不予公开的裁判文书类型,包括涉及国家秘密的、未成年人犯罪的、以调解方式结案或者确认人民调解协议效力的(但为保护国家利益、社会公共利益、他人合法权益确有必要公开的除外)、离婚诉讼或者涉及未成年子女抚养监护的以及人民法院认为不宜在互联网公布的其他情形。
- 「法宝推荐」页面中的判决书跟优秀案例、经典案例等的判决书是不一致的,字段不一样,所以这里可以只对「法宝推荐」的判决书进行分析。(跟法宝确定过这一点)
- code不一样,title一样,case_no不一样:这种情况不属于重复案件,可能是因为当事人1对当事人2的诉讼标的不一样,比如商标1号侵权,商标2号也侵权,两个商标就是两个起诉案件。
CLI.C.310641014 北京红舞鞋文化艺术有限公司与田相琼侵害商标权纠纷一审民事判决书 https://www.pkulaw.com/pfnl/c05aeed05a57db0ad760f4831d13f5bc6a4ad6f8d8a70355bdfb.html 知识产权与竞争纠纷知识产权权属、侵权纠纷商标权权属、侵权纠纷侵害商标权纠纷 (2020)川09知民初172号
CLI.C.310641023 北京红舞鞋文化艺术有限公司与田相琼侵害商标权纠纷一审民事判决书 https://www.pkulaw.com/pfnl/c05aeed05a57db0a0bd183b5bb837625170214f003b81c5ebdfb.html 知识产权与竞争纠纷知识产权权属、侵权纠纷商标权权属、侵权纠纷侵害商标权纠纷 (2020)川09知民初173号
- 2013年和2019年商标法中,code、title、case_no都一样,只有year不一样,
2019 CLI.C.95010734 惠而浦资产公司与浙江惠而浦电器有限公司侵害商标权纠纷一审民事判决书 https://www.pkulaw.com/pfnl/a6bdb3332ec0adc49e3d30e9bf6df5a15ac85763ad60687ebdfb.html 知识产权与竞争纠纷知识产权权属、侵权纠纷商标权权属、侵权纠纷侵害商标权纠纷 (2018)浙02民初1495号
2013 CLI.C.95010734 惠而浦资产公司与浙江惠而浦电器有限公司侵害商标权纠纷一审民事判决书 https://www.pkulaw.com/pfnl/a6bdb3332ec0adc49e3d30e9bf6df5a15ac85763ad60687ebdfb.html 知识产权与竞争纠纷知识产权权属、侵权纠纷商标权权属、侵权纠纷侵害商标权纠纷 (2018)浙02民初1495号
- 第四步:替换干扰字符。由于将2019html和2013html进行合并后,数据量很大,在excel进行替换会直接崩掉,所以使用python进行操作。
import pandas as pd
df = pd.read_excel (r'/Users/fubo/Desktop/法律项目/subject合并1.xlsx')
df.replace(':',':')
df.replace(': ',':')
df.replace(' :',':')
df.replace('(','(')
df.replace(')',')')
#写入文件,使用xlsxwriter模块,添加指定参数engine='xlsxwriter',自动去除非法字符。
import xlsxwriter
df.to_excel('subject_output_2.xlsx', engine='xlsxwriter')
- 第五步:初步人工检查。由于有一些单元格直接就是无意义符号等,还有几十个判决书是优秀案例之类的,数据字段基本对不上的,就直接清洗掉了。然后将表格从第一列开始,进行排序,看哪些行是有问题的,手动进行调整(就是删除无效单元格,移动到合适列的繁琐工作)。
到这里,大部分字段都是提取出来的了,就是要将没有对齐的行进行人工检查修改,这一步重复性检查工作是笔者最不喜欢的工作,暂且看看能不能交给其他人完成…
经过上述处理,最后得到file:subject_未人工整理_0810.xlsx,all_未人工整理_0811.xlsx,两张表格。
到这一步,虽然还是有很多要完善的点,但还是终于将数据爬下来了,想起来了之前跟一位计软的大佬聊起这个数据任务,当时他说:“这个事最后你还是需要手动处理很多东西”,我当时还不以为意,以为很简单,TYTS!
但是现在看来一个看似简单字段需求,居然这么麻烦,是我太菜了?还是本来就这么多工作量?不知道大佬会如何解决这个问题?尝试使用实体识别等机器学习方法?
根据当事人爬取天眼查公司数据
思路分析
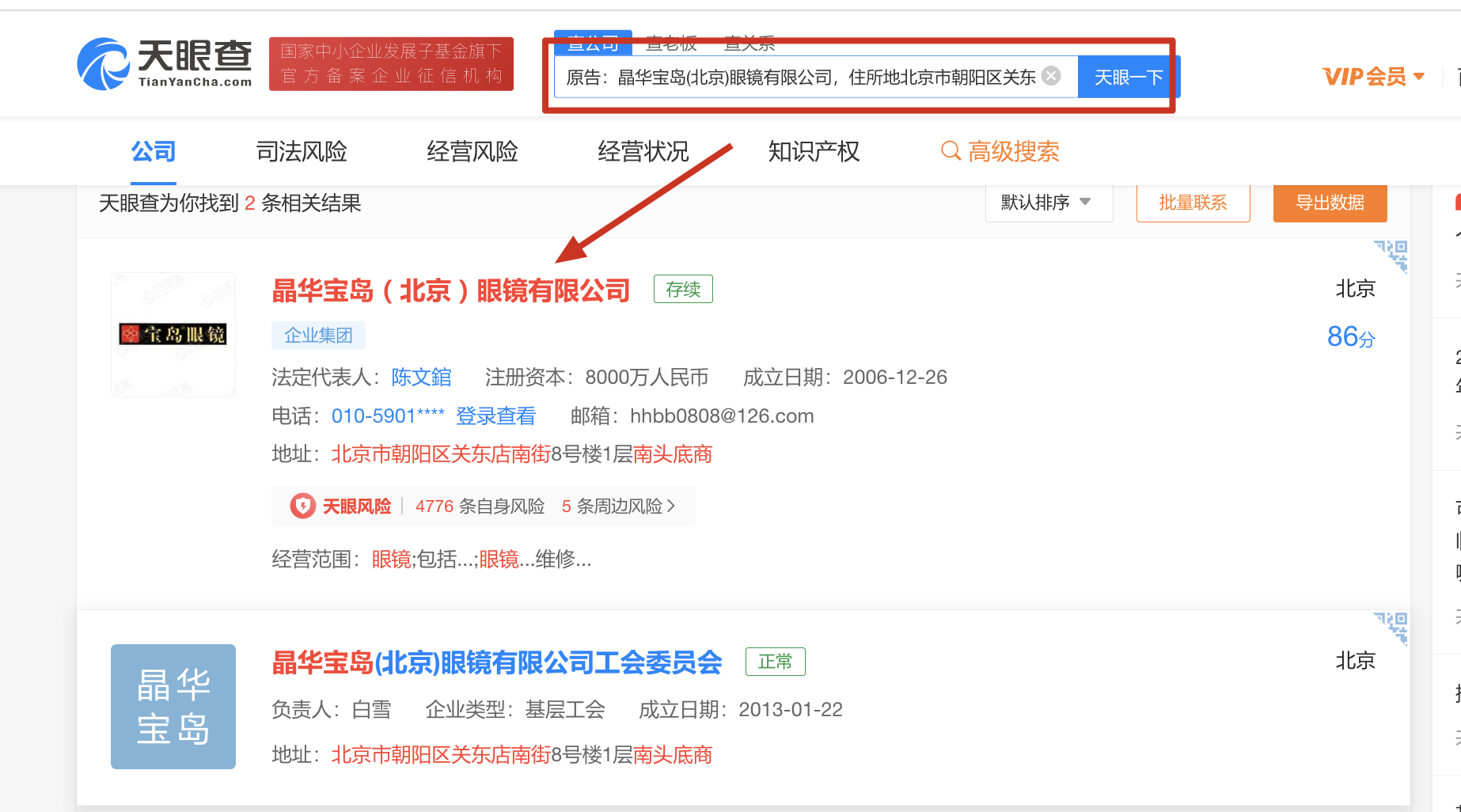
下一步任务就是,获取当事人公司的相关企业信息了。每一个案件都涉及多个当事人公司,将这些公司名称作为关键词去天眼查检索,并将检索到的公司信息都爬取下来。具体思路如下:
- 将上述判决书当事人所在列的公司字段对齐了。(不用把公司名称单独提取出来也可以,有多余信息也可以在天眼查准确检索出来)(update:杂项还是要去带掉才可以)

-
将所有要爬取的当事人用excel去重后,整合成txt文本
-
将txt文本中的每一行公司名称作为关键词对天眼查爬虫,并保存到mysql数据库。这里由于公司名称存在不完全一致的问题,天眼查不一定精确匹配,所以将检索到的几个公司都爬取下来,再去做匹配
-
将爬取下来的公司数据库下载成excel,根据函数对天眼查公司和判决书当事人公司进行模糊匹配。这里使用的是excel的函数,比较复杂,大概思路就是将文本切成一个字一个字,再按照相似度进行匹配。
=INDIRECT("A"&RIGHT(MAX(MMULT(ISNUMBER(FIND(MID(C2,TRANSPOSE(ROW(INDIRECT("1:"&LEN(C2)))),1),A2:A10875))*1,ROW(INDIRECT("1:"&LEN(C2)))^0)/1%%%+ROW(A2:A10875)),5))
字段需求
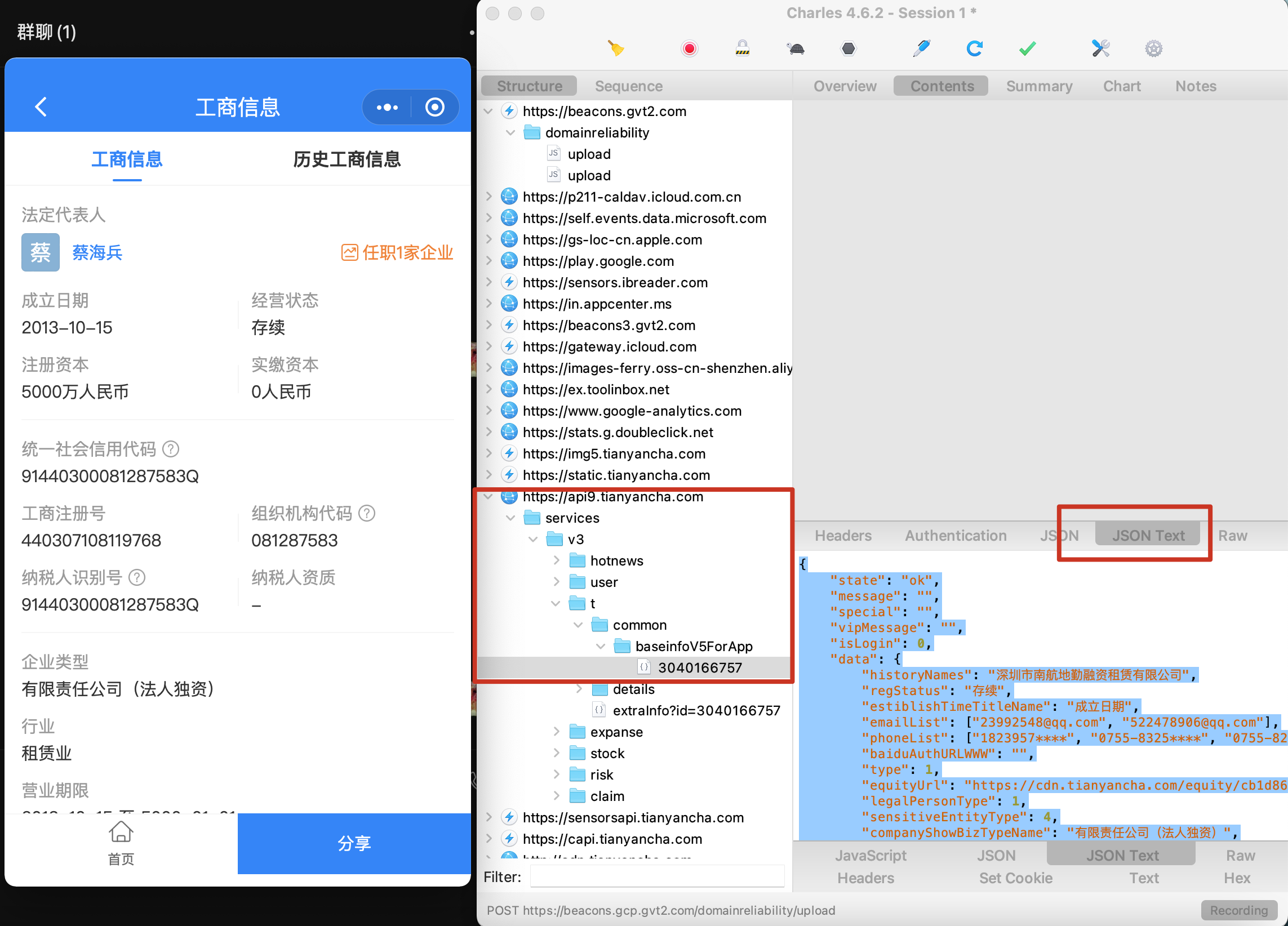
天眼查爬虫起家的公司批量爬取也不是很好搞,笔者用了小程序抓包,IP代理池,借用几个天眼查账号获取cookies才解决了大部分的反爬机制,目前已爬取的字段如下表如下(公司企业基本信息表,高管表和股东表):

目前还需要增加的字段,如下图所示的:

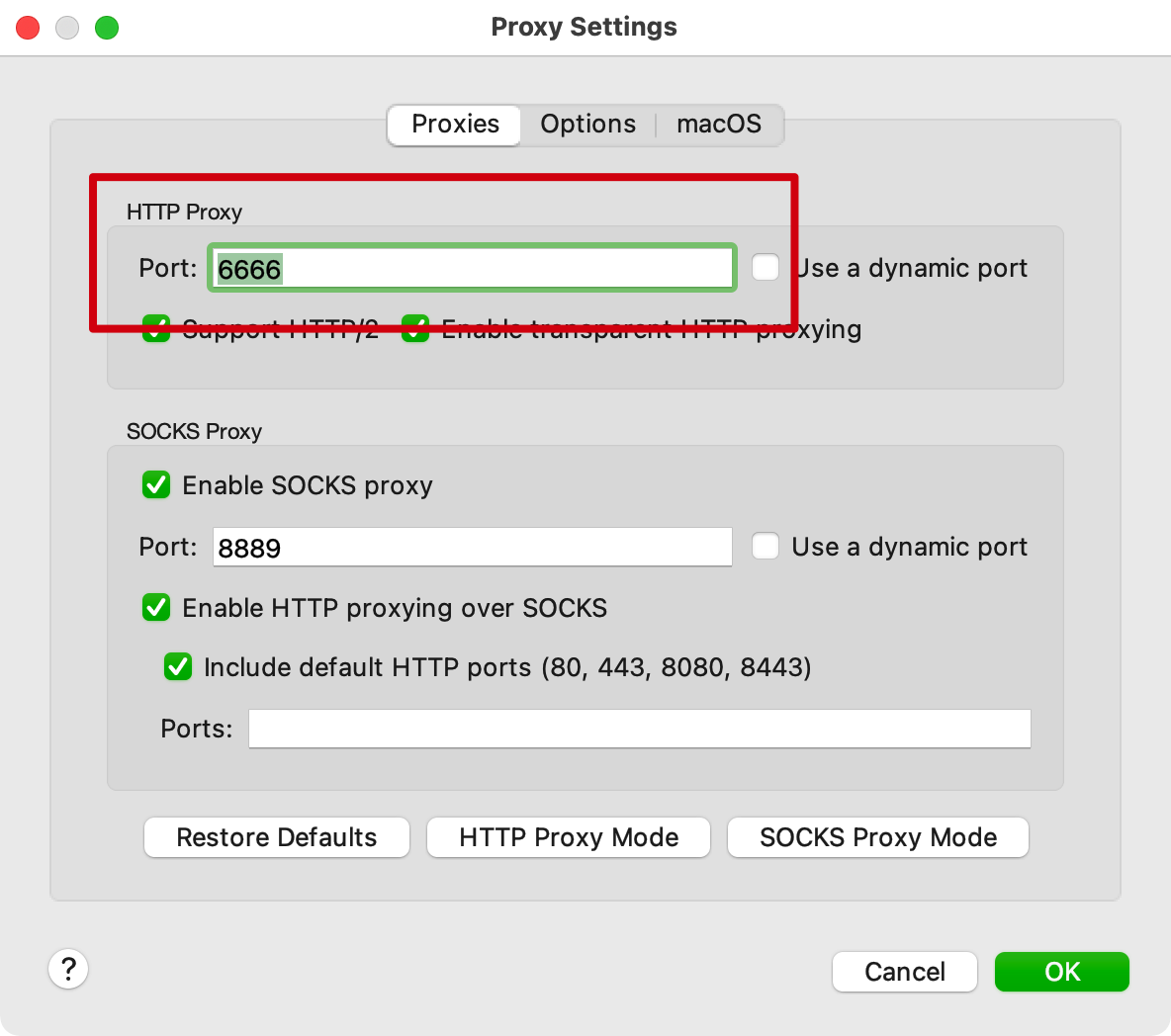
首先使用Mac的Charles进行抓包,今天打开居然抓不到了,试了很多方法,才发现是端口占用问题,从8888修改为6666,且将MacOS的stocks代理打开。
使用小程序查看

可以看到这些新需要的字段:
- 核准日期
"approvedTime": 1577721600000, timenum = 1577721600 #取前10位,也就是/1000 timestruct = time.localtime(timenum) strTime = time.strftime("%Y-%m-%d",timestruct) print(strTime) #2019-12-31 # 公司核准时间 target.approved_time = src.get('approvedTime', '-') - 人员规模
"staffNumRange": "小于50人", - 参保人数
"socialStaffNum": 7031, - 登记机关:
"regInstitute": "深圳市市场监督管理局", - 天眼评分:
"companyScore": { "claimScoreRange": 5, "claimAddScore": 0, "originalPercentileScore": 83, "percentileScoreImg": "https://static.tianyancha.com/app/icon/score_83.jpg", "text": "天眼评分是客户了解企业实力最直观的方式,认证后至多加5分" },
Todo等公司的list清理好了之后,就可以开始爬取。需要注意的是,天眼查爬虫程序执行的时候需要关闭代理,不然识别不了天眼查的cookies。同时,数据库插入字段还有一个bug,但不影响数据插入,待改bug。
Wind判断公司是否上市及市值
获取到公司的信息之后,需要在Wind下载所有上市公司的列表以及从2013-2019年的市值,再跟字段中的所有当事人公司进行匹配,判断是否上市以及当年的市值。
这个数据抓取陆续忙碌了这么久了,到今天终于处理得
差不多了。最大的感受就是,很多看似简单的事情做起来其实并没想象中那么简单,需要很多的耐心去尝试,也需要很多的细心去修改。