需求
本项目是法律相关的科研项目,需要通过深圳市律师协会官方网站 (szlawyers.com)进入北大法宝的案例库下载商标法相关的判决书,并提取相关的结构化数据,以供进一步学术研究。
所以,主要包括两个数据需求:
一、判决书文本:2019年和2013年商标法
1、搜索最新版本的商标法的相关判决书,搜索“商标法”,点击“中华人民共和国商标法(2019修正)”
2、查看第五十八条,并点击司法案例(有4203 篇,公开了2116篇,通过图表,可以看到 2019(335篇)、2020(941篇)、2021(703篇)、2022(109篇))

3、下载2019年11月1日(新商标法实施日期)至今2022年5月1日的全部判决书,这是最新商标法的判决书
4、搜索2013年版本的商标法的相关判决书,搜索“商标法”,点击“中华人民共和国商标法(2013修正)”
5、查看第五十八条,并点击司法案例(有4204 篇,公开了2072篇,通过图表,可以看到 2017(452篇)、2018(596篇)、2019(523篇))

6、下载2017年5月1日至2019年10月31日的全部判决书,这是旧版商标法的判决书
二、通过判决书文本提取结构化字段。
关于目标字段,分为两个部分:一部分是可以通过HTML解析到的;一部分是需要进一步通过文本分析得到的。
目前已经提取到的数据字段如下:
| code 法宝引证码 | city 法院城市 |
|---|---|
| title 判决书名称 | start_date 受理日期 |
| href 原文链接 | subject_1 当事人1 |
| case_reason 案由 | subject_1_rep 当事人1_代表人 |
| case_no 案号 | subject_2 当事人2 |
| judges 全部审判法官 | subject_2_rep 当事人2_代表人 |
| instrument_type 文书类型 | subject_text 当事人部分完整文本 |
| completion_date 审结日期 | subject_1_dict 当事人字典(多个当事人情况) |
| case_type 案件类型 | subject_2_dict 当事人字典(多个当事人情况) |
| proceeding 审理程序 | subject_1_list_true 所有的当事人1 |
| law_firms 代理律师/律所 | subject_1_rep_list_true_set 所有的当事人1_代表人 |
| keywords 权责关键词 | subject_2_list_true 所有的当事人2 |
| legal_count 法律依据_条数 | subject_2_rep_list_true 所有的当事人2_代表人 |
| legal 法律依据 | case_result 完整的裁判结果文本 |
| text 完整的正文文本 | eco_fee 被告向原告赔偿费 |
| court 审理法院 | eco_fee_beigao 赔偿人_被告 |
| court_level 法院级别 | eco_fee_yuangao 被赔偿人_被告 |
| province 法院省份 |
还有一部分字段由于尚缺乏判断规则还没进行提取
- 受理费及负担方
- ToB or ToC
- 是否Internet-based
获取判决书
关于获取判决书的文本,官网提供了TXT、HTML等下载格式,为了便于字段解析,笔者判断以HTML格式存储最为方便。有两种思路:
- 思路1:通过爬虫获取URL,逐个访问URL解析数据
-
思路2:通过正规渠道下载HTML,基于本地HTML解析数据
思路1:爬虫
Selenium破解滑块验证,获取URL
笔者首先尝试使用爬虫来获取数据,通过分析北大法宝的页面(笔者这里是i通过律协的账号登录,所以url的头缀是szlx,正常通过pkulaw官网登录时,url是www),发现这个网站在超过20页时,设置了反爬,每次翻页的时候都需要使用滑块验证,所以需要使用到selenium模拟自动化登录,再配合图像识别破解滑块验证。
以抓取2019商标法的判决书为例,大概的思如下:
1、模拟登录,输入账号密码
2、模拟点击,进入到要下载的页面
3、前20页翻页不需要滑块验证,从21页开始借鉴了CSDN上的文章破解了滑块验证
4、每次翻页的时候,抓取每个页面上10条判决书的URL(后面在基于所抓取的URL,一个一个进行访问解析并获取数据)
此部分:「模拟登录,破解滑块验证,获取每个判决书URL」的完整代码如下:(注意:使用selenium需要下载对应版本的chromedriver)
# -*- coding: utf-8 -*-
import random
import six
import os,base64
import time, re
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.action_chains import ActionChains
from PIL import Image
import requests
import io
from io import BytesIO
import cv2
class qjh(object):
def __init__(self):
chrome_option = webdriver.ChromeOptions()
self.driver = webdriver.Chrome(executable_path=r"/Users/fubo/Desktop/Git/Law_projects/chromedriver", chrome_options=chrome_option)
self.driver.set_window_size(1440, 900)
# 在这里修改要爬取的页面
self.allurl=[int(i) for i in range(1,20)]
# 核心函数
def core(self):
url = "https://szlx.pkulaw.com/clink/pfnl/chl/937235cafaf2a66fbdfb/58_0_0_0.html"
self.driver.get(url)
# 模拟登录,输入账号密码
zhanghao = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="email-phone"]'))
)
zhanghao.send_keys('XXX') # 输入账号XXX,需要替换成自己的账号
mima = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="password"]'))
)
mima.send_keys('XXX') # 输入密码XXX,需要替换成自己的密码
time.sleep(1) # 等待加载
denglu = WebDriverWait(self.driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//a[@class="btn-submit"]')))
denglu.click()
time.sleep(2) # 等待加载
#进入法宝推荐界面
tuijian = WebDriverWait(self.driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//a[@title="法宝推荐 (2095)"]')))
tuijian.click()
more = WebDriverWait(self.driver, 10).until(
EC.element_to_be_clickable((By.XPATH, '//a[i[@class="c-icon c-eye"]]')))
more.click()
# 开始翻页
# for i in self.allurl:
# time.sleep(2)
# WebDriverWait(self.driver, 1000).until(
# ec.element_to_be_clickable((By.ID, 'qr_submit_id'))
#
# )
for i in self.allurl:
input = WebDriverWait(self.driver,100) .until(
EC.presence_of_element_located((By.XPATH,'//*[@name="jumpToNum"]')))
input.send_keys(i)
# element1 = self.driver.find_element('div/a[@class="jumpBtn"]')
# self.driver.execute_script("arguments[0].click();", element1)
button = WebDriverWait(self.driver,100).until(EC.element_to_be_clickable ((By.XPATH,'//a[@class="jumpBtn"]')))
self.driver.execute_script("arguments[0].click();", button)
# button.click()
time.sleep(4)#等待加载
# -----------------
# # 破解滑块,后21页需要
# cut_image_url, cut_location = self.get_image_url('//div[@class="cut_bg"]')
# cut_image = self.mosaic_image(cut_image_url, cut_location)
# cut_image.save("cut.jpg")
#
# self.driver.execute_script(
# "var x=document.getElementsByClassName('xy_img_bord')[0];"
# "x.style.display='block';"
# )
# cut_fullimage_url = self.get_move_url('//div[@class="xy_img_bord"]')
# resq = base64.b64decode(cut_fullimage_url[22::])
#
# file1 = open('2.jpg', 'wb')
# file1.write(resq)
# file1.close()
#
# res=self.FindPic("cut.jpg", "2.jpg")
#
# res=res[3][0]#x坐标
#
# self.start_move(res)
# time.sleep(2) # 等待加载
#-----------------
arts=[]
# 开始循环并保存文章
elems = self.driver.find_elements_by_xpath("//ul/li/div/div/h4/a[1]")
for elem in elems:
arts.append(''+elem.get_attribute("href"))
print(arts)
time.sleep(2) # 等待加载
def FindPic(self,target, template):
"""
找出图像中最佳匹配位置
:param target: 目标即背景图
:param template: 模板即需要找到的图
:return: 返回最佳匹配及其最差匹配和对应的坐标
"""
target_rgb = cv2.imread(target)
target_gray = cv2.cvtColor(target_rgb, cv2.COLOR_BGR2GRAY)
template_rgb = cv2.imread(template, 0)
res = cv2.matchTemplate(target_gray, template_rgb, cv2.TM_CCOEFF_NORMED)
value = cv2.minMaxLoc(res)
return value
def get_move_url(self, xpath):
#得到滑块的位置
link = re.compile(
'background-image: url\("(.*?)"\); ') # 严格按照格式包括空格
elements = self.driver.find_elements_by_xpath(xpath)
image_url = None
for element in elements:
style = element.get_attribute("style")
groups = link.search(style)
url = groups[1]
image_url = url
return image_url
def get_image_url(self, xpath):
#得到背景图片
link = re.compile('background-image: url\("(.*?)"\); width: 30px; height: 100px; background-position: (.*?)px (.*?)px;')#严格按照格式包括空格
elements = self.driver.find_elements_by_xpath(xpath)
image_url = None
location = list()
for element in elements:
style = element.get_attribute("style")
groups = link.search(style)
url = groups[1]
x_pos = groups[2]
y_pos = groups[3]
location.append((int(x_pos), int(y_pos)))
image_url = url
return image_url, location
# 拼接图片
def mosaic_image(self, image_url, location):
resq = base64.b64decode(image_url[22::])
file1 = open('1.jpg', 'wb')
file1.write(resq)
file1.close()
with open("1.jpg", 'rb') as f:
imageBin = f.read()
# 很多时候,数据读写不一定是文件,也可以在内存中读写。
# BytesIO实现了在内存中读写bytes,创建一个BytesIO,然后写入一些bytes:
buf = io.BytesIO(imageBin)
img = Image.open(buf)
image_upper_lst = []
image_down_lst = []
count=1
for pos in location:
if pos[0]>0:
if count <= 10:
if pos[1] == 0:
image_upper_lst.append(img.crop((abs(pos[0]-300), 0, abs(pos[0]-300) + 30,100)))
else:
image_upper_lst.append(img.crop((abs(pos[0] - 300), 100, abs(pos[0] - 300) + 30, 200)))
else:
if pos[1] == 0:
image_down_lst.append(img.crop((abs(pos[0]-300), 0, abs(pos[0]-300) + 30,100)))
else:
image_down_lst.append(img.crop((abs(pos[0] - 300), 100, abs(pos[0] - 300) + 30, 200)))
elif pos[0]<=-300:
if count <= 10:
if pos[1] == 0:
image_upper_lst.append(img.crop((abs(pos[0]+300), 0, abs(pos[0]+300) + 30,100)))
else:
image_upper_lst.append(img.crop((abs(pos[0] +300), 100, abs(pos[0]+ 300) + 30, 200)))
else:
if pos[1] == 0:
image_down_lst.append(img.crop((abs(pos[0] + 300), 0, abs(pos[0] + 300) + 30, 100)))
else:
image_down_lst.append(img.crop((abs(pos[0] + 300), 100, abs(pos[0] + 300) + 30, 200)))
else:
if count <= 10:
if pos[1] == 0:
image_upper_lst.append(img.crop((abs(pos[0] ), 0, abs(pos[0] ) + 30, 100)))
else:
image_upper_lst.append(img.crop((abs(pos[0] ), 100, abs(pos[0] ) + 30, 200)))
else:
if pos[1] == 0:
image_down_lst.append(img.crop((abs(pos[0] ), 0, abs(pos[0] ) + 30, 100)))
else:
image_down_lst.append(img.crop((abs(pos[0] ), 100, abs(pos[0] ) + 30, 200)))
count+=1
x_offset = 0
# 创建一张画布,x_offset主要为新画布使用
new_img = Image.new("RGB", (300, 200))
for img in image_upper_lst:
new_img.paste(img, (x_offset, 0))
x_offset += 30
x_offset = 0
for img in image_down_lst:
new_img.paste(img, (x_offset, 100))
x_offset += 30
return new_img
def start_move(self, distance):
element = self.driver.find_element_by_xpath('//div[@class="handler handler_bg"]')
# 按下鼠标左键
ActionChains(self.driver).click_and_hold(element).perform()
time.sleep(0.5)
while distance > 0:
if distance > 10:
# 如果距离大于10,就让他移动快一点
span = random.randint(10,15)
else:
# 快到缺口了,就移动慢一点
span = random.randint(2, 3)
ActionChains(self.driver).move_by_offset(span, 0).perform()
distance -= span
time.sleep(random.randint(10, 50) / 100)
ActionChains(self.driver).move_by_offset(distance, 1).perform()
ActionChains(self.driver).release(on_element=element).perform()
if __name__ == "__main__":
h = qjh()
h.core()
Request遍历URL,解析HTML
但通过爬虫获取URL再逐个访问URL解析数据的思路,这个过程中遇到了两个难题:
1、笔者通过上述程序将2019年商标法2000多条公开判决书的URL都爬下来了。但其中不知为何存在多个重复的URL【待解决】,去重后只剩下1400多条。这是一个很大的问题,因为如果无法保证数据完整性,就影响了研究的准确性。

2、笔者通过所爬取的URL,通过request和cookies的方式逐个访问URL,然后解析数据。笔者编程尝试了一下,大部分字段都可以完整爬取到,下图是完成的几百个测试数据截图:
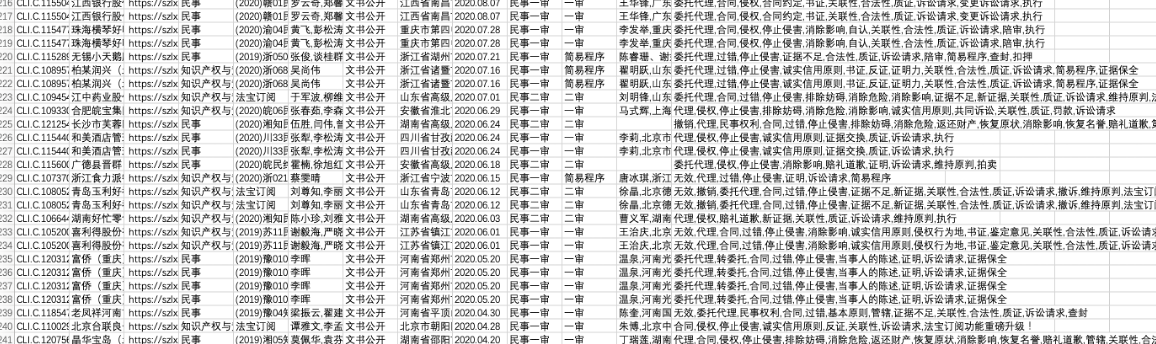
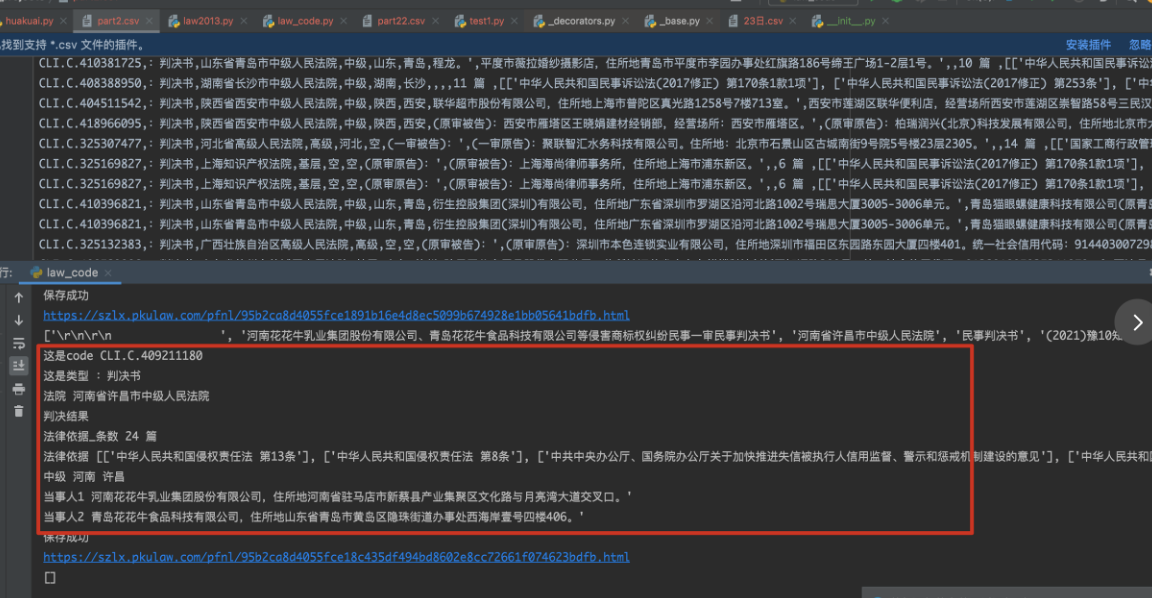
但是代码还没测试完,这个账号就被封了…说明了法宝的风险机制还是比较严格,要爬取的数据量比较大,request请求的思路不太行得通

通过request访问URL解析数据的不完整代码如下:
# -*- encoding:utf-8 -*-
import csv
import random
import requests
from lxml import etree
import re
from bs4 import BeautifulSoup
from pathlib import Path
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'}
cookies ={'Cookie':
'activeRegisterSource=; authormes=28f756df11b64b43ca9e7b75b4360ba071f17e640dad3fd063b0147764b4420a75d6e28a98d67008bdfb; xCloseNew=24; KC_ROOT_LOGIN=1; KC_ROOT_LOGIN_LEGACY=1; pkulaw_v6_sessionid=3onaddwlj3g4bec2dx04wmhh; Hm_lvt_6f2378a3818b877bcf6e084e77f97ae1=1658551068,1658565609,1658583356,1658624464; Hm_lvt_8266968662c086f34b2a3e2ae9014bf8=1658551068,1658565609,1658580776,1658624464; userislogincookie=true; Hm_up_8266968662c086f34b2a3e2ae9014bf8=%7B%22uid_%22%3A%7B%22value%22%3A%2207363b75-8f34-eb11-b390-00155d3c0709%22%2C%22scope%22%3A1%7D%2C%22ysx_yhqx_20220602%22%3A%7B%22value%22%3A%220%22%2C%22scope%22%3A1%7D%2C%22ysx_yhjs_20220602%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22ysx_hy_20220527%22%3A%7B%22value%22%3A%2206%22%2C%22scope%22%3A1%7D%7D; Hm_lpvt_6f2378a3818b877bcf6e084e77f97ae1=1658628608; Hm_lpvt_8266968662c086f34b2a3e2ae9014bf8=1658628608'
}
url_list = []
def open_txt():
with open("list1.txt", "r", encoding="utf-8") as f:
for line in f.readlines():
url_list.append(line.replace('\n', ''))
def send_request(url):
resp = requests.get(url, cookies = cookies, headers=headers)
resp.encoding = 'utf-8'
return resp.text
def save(film_content, ):
with open('const.csv', 'a+', newline='', encoding='gb18030') as f:
writer = csv.writer(f)
writer.writerow(film_content)
print('保存文件成功')
open_txt()
items = []
# xpath解析
num_select = 10
for num_text, url in enumerate(url_list[:50:]):
# if num_text+1==565:
# num_select=9
title = '';case_reason = '';case_no = '';judges = '';instrument_type = '';court = '';completion_date = '';case_type = '';proceeding = '';law_firms = '';keywords = '';court_level = '';province = ''
# e = etree.HTML(send_request(url)) # 类型转换 将str类型转换成class 'lxml.etree._Element'
e = etree.parse('url', etree.HTMLParser())
text = e.xpath("//div[@class='fulltext']//text()")
text = " ".join(text).strip()
# print(text)
# print(send_request(url))
if e.xpath(f"//div[@class='fields']/ul//li[1]//text()"):
try:
url_one = 'https://szlx.pkulaw.com/AssociationMore/pfnl/' + url.split('/')[-1].split('.')[0] + '/19_0.html'
url_text = requests.get(url=url_one, headers=headers)
obj3 = re.compile(r"本案法律依据 (.*?)<", re.S)
legal_count = obj3.findall(url_text.text)[0]
list11 = etree.HTML(url_text.text)
url_text_title = list11.xpath('//*[@id="rightContent"]/div/div/div[2]/ul/li')
legal = []
for i in url_text_title:
url_text_title1 = i.xpath('./div/div/h4/a//text()')
legal.append(url_text_title1)
# print(url_text_title1)
except:
url_text_title1 = ''
legal_count = ''
legal = ''
# 当事人
text = e.xpath('//div[@id="divFullText"]//text()')
wor = str(text)
word = wor.split('审理经过')[0]
try:
if ('原告:' in word):
obj1 = re.compile(r"原告:(.*?),", re.S)
obj2 = re.compile(r"被告:(.*?),", re.S)
subject_1 = obj1.findall(word)[0]
subject_2 = obj2.findall(word)[0]
obj66 = re.compile(r"原告:.*?,(.*?)。", re.S)
obj65 = re.compile(r"被告:.*?,(.*?)。", re.S)
yuangao_adress = obj66.findall(word)[0].replace("\\u3000", "")
beigao_adress = obj65.findall(word)[0].replace("\\u3000", "")
elif ('上诉人' in word):
obj1 = re.compile(r"上诉人(.*?),", re.S)
obj2 = re.compile(r"被上诉人(.*?),", re.S)
subject_1 = obj1.findall(word)[0]
subject_2 = obj2.findall(word)[0]
obj66 = re.compile(r"上诉人.*?,(.*?)。", re.S)
obj65 = re.compile(r"被上诉人.*?,(.*?)。", re.S)
yuangao_adress = obj66.findall(word)[0].replace("\\u3000", "")
beigao_adress = obj65.findall(word)[0].replace("\\u3000", "")
elif ('再审申请人' in word):
obj1 = re.compile(r"再审申请人:(.*?),", re.S)
obj2 = re.compile(r"被申请人:(.*?),", re.S)
subject_1 = obj1.findall(word)[0]
subject_2 = obj2.findall(word)[0]
obj66 = re.compile(r"再审申请人:.*?,(.*?)。", re.S)
obj65 = re.compile(r"被申请人:.*?,(.*?)。", re.S)
yuangao_adress = obj66.findall(word)[0].replace("\\u3000", "")
beigao_adress = obj65.findall(word)[0].replace("\\u3000", "")
except:
subject_1 = ''
subject_2 = ''
yuangao_adress = ''
beigao_adress = ''
obj4 = re.compile(r"判决如下:(.*?)落款", re.S)
result_1 = obj4.findall(word)
case_result = ''.join(result_1).replace("'", "").replace("\\u3000", "").replace(',', '').strip()
code = e.xpath('//*[@id="gridleft"]/div/div[1]/div[1]/span/a/text()')[0]
box_list = str(e.xpath('//*[@id="gridleft"]/div/div[1]/div[3]//text()'))
instrument_type = re.compile(r"文书类型(.*?)公开类型", re.S)
instrument_type = ''.join(instrument_type.findall(box_list)).replace('\\r\\n ', '').replace('\\t', '').replace(
',', '').replace("'",
'').replace(
' ', '')
for i in range(2, 6):
contant = e.xpath(f"//div[@class='fields']/ul//li[{i}]//text()")
# print(contant)
# print("".join(contant).split())
if "".join(contant).split()[0] == '审理法官:':
num = 11
break
else:
num = 10
for i in range(2, 10):
contant = e.xpath(f"//div[@class='fields']/ul//li[{i}]//text()")
if "".join(contant).split()[0] == '代理律师/律所:':
# print("".join(contant).split()[1::])
flag = 1
break
else:
flag = 0
# print(flag)
if flag == 0:
num -= 1
code = e.xpath("//div[@class='info']/span/a/text()")
code = "".join(code)
title = e.xpath("//div/h2/text()")
title = "".join(title).strip()
case_reason = e.xpath("//div[@class='fields']/ul/li[@class='row'][1]/div[@class='box']/a/text()")
case_reason = "".join(case_reason)
case_no = e.xpath("//div[@class='fields']/ul[1]//li//@title")[1]
text = e.xpath("//div[@class='fulltext']/div//text()")
text = " ".join(text).strip()
# print(num)
for i in range(2, num):
contant = e.xpath(f"//div[@class='fields']/ul//li[{i}]//text()")
data = "".join(contant).split()[0]
# print("".join(contant).split()[0][0:5:])
# print("".join(contant).split())
if data == '审理法官:':
judges = "".join(contant).split()[1::]
# print(judges)
judges = ",".join(judges)
elif data == '文书类型:':
instrument_type = "".join(contant).split()[1]
elif data == '公开类型:':
instrument_type = "".join(contant).split()[1]
elif data == '审理法院:':
court = "".join(contant).split()[1]
if ("最高" in court):
court_level = '最高'
province = '空'
city = '空'
elif ("高级" in court):
court_level = '高级'
if ("省" in court):
province = court.split('省')[0]
if ("市" in court):
city = court.split("省")[1].split('市')[0]
else:
city = '空'
elif ("自治州" in court):
province = court.split('自治州')[0]
if ("市" in court):
city = court.split("自治州")[1].split('市')[0]
elif ("市" in court):
province = court.split('市')[0]
city = '空'
else:
city = '空'
province = '空'
elif ("中级" in court):
court_level = '中级'
if ("省" in court):
province = court.split('省')[0]
if ("市" in court):
city = court.split("省")[1].split('市')[0]
elif ("自治州" in court):
province = court.split('自治州')[0]
if ("市" in court):
city = court.split("自治州")[1].split('市')[0]
elif ("市" in court):
province = court.split('市')[0]
city = '空'
else:
city = '空'
province = '空'
elif ("知识产权" in court):
court_level = '专门'
city = '空'
province = '空'
elif ("区" or "县" in court):
court_level = '基层'
if ("省" in court):
province = court.split('省')[0]
if ("市" in court):
city = court.split("省")[1].split('市')[0]
elif ("自治州" in court):
province = court.split('自治州')[0]
if ("市" in court):
city = court.split("自治州")[1].split('市')[0]
elif ("市" in court):
province = court.split('市')[0]
city = '空'
else:
city = '空'
province = '空'
else:
court_level = ''
city = '空'
province = '空'
elif data[0:5:] == '审结日期:':
completion_date = data[5::]
elif data == '案件类型:':
case_type = "".join(contant).split()[1]
elif data == '审理程序:':
proceeding = "".join(contant).split()[1]
elif data == '代理律师/律所:':
law_firms = "".join(contant).split()[1::]
law_firms = ",".join(law_firms).replace(',,', '').replace(',;', '')
elif data == '权责关键词:':
keywords = "".join(contant).split()[1::]
keywords = ",".join(keywords)
item = [num_text + 1, code, title, url, case_reason, case_no, judges, instrument_type, court, court_level,
province, city, completion_date, case_type,
proceeding, law_firms, keywords,instrument_type,subject_1,subject_2,case_result,legal_count,legal, text]
print(f"第{num_text + 1}个爬取成功,titile是{title}")
save(item)
基于上述难题,笔者想能否通过以下可能的方式解决问题:
(1)【不确定是否可做】关于封号问题,可能可以通过购买IP代理池,不断变换IP爬取数据,解决封号问题(未尝试过)
(2)【可做】通过正规渠道直接下载HTML文件到本地,再编程利用文本分析提取字段。接下来笔者将尝试这个方式。
思路2:正规渠道
笔者首先通过律协的渠道联系到了北大法宝的负责经理,开通了北大法宝的下载账号,但每天限制最多下载200篇,且批量下载一次只能下载10篇,相当于总共4000多篇判决书要20多天,点击400多次才可以完成… 笔者对于这种枯燥的人工点击极其排斥,即使点击次数也没有特别多,所以有两个解决方式:
解决方式1:联系了法宝的经理,咨询是否可以后台批量下载,至今一周过去了,中间催促了一两次,但仍在等待回复中…
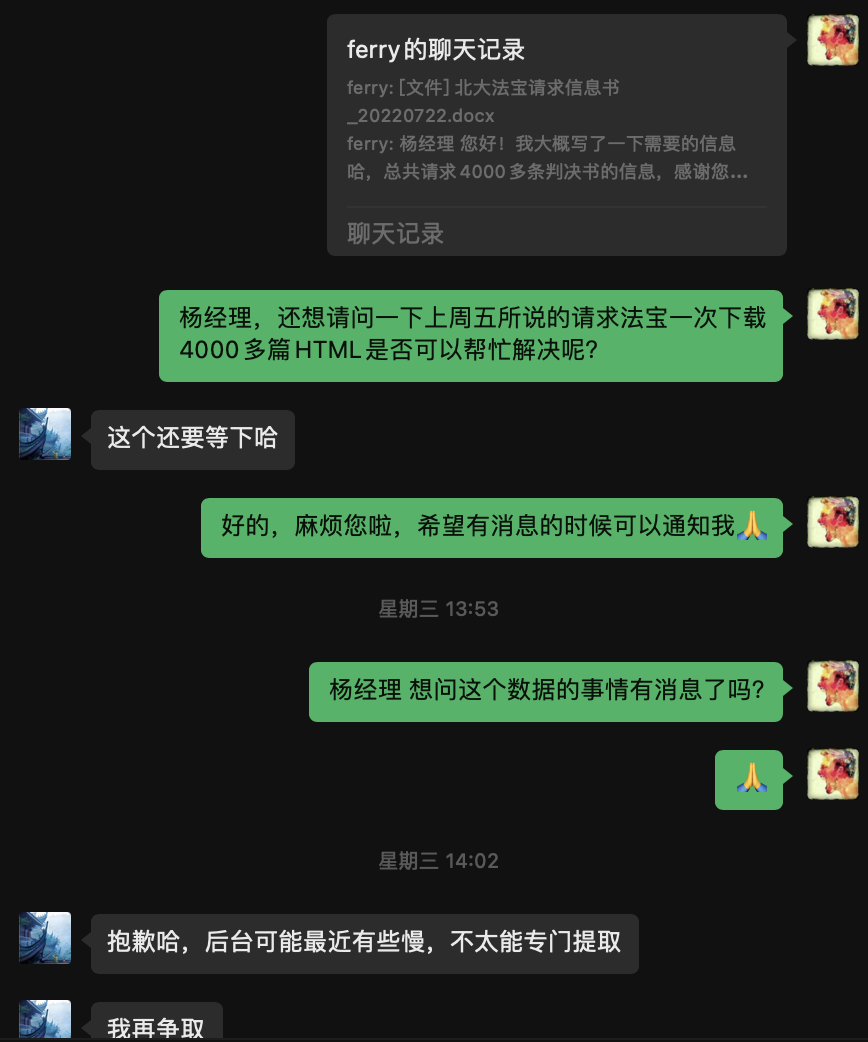
解决方式2:如果没办法通过后台直接下载,那只能通过自动化程序编程来完成这种枯燥的工作了,目前的思路是使用pyautogui完成自动化点击,笔者曾使用这个工具下载wind的数据,解放了双手。但目前由于法宝是网页端,似乎使用selenium就可以完成自动化,pyautogui更多是用来解决非网页端的自动化工具。

但这样还是被限制每天下载200篇,下载20天,需要尝试是否有办法搞多几个账号…
在等待反馈的过程中,笔者手动先下载了250多个HTML到本地,然后利用编程读取字段。

解析HTML获取字段
获取了本地HTML后,需要遍历文件夹中的HTML,进行解析,获取需要的字段数据,这个需求听着简单,但实际操作中却很麻烦,主要是因为要获取的文本没有太多结构化的规律,所以需要自己找规律,不断尝试,以覆盖多种情况。主要的方法思路如下:
1、对每个字段观察判决书中的情况,总结多种情况,得到提取字段的判断规则和规律。
2、使用Xpath提取HTML的字段,使用正则表达式完成对于字段规律的编程,这里可以借助八爪鱼、Regex、正则生成代码、JS正则工具等工具辅助写正则表达式。
3、获取后使用python相关的数据处理工具进行数据处理。
最后得到了前文所说的字段数据,基本完成了数据需求的编程。
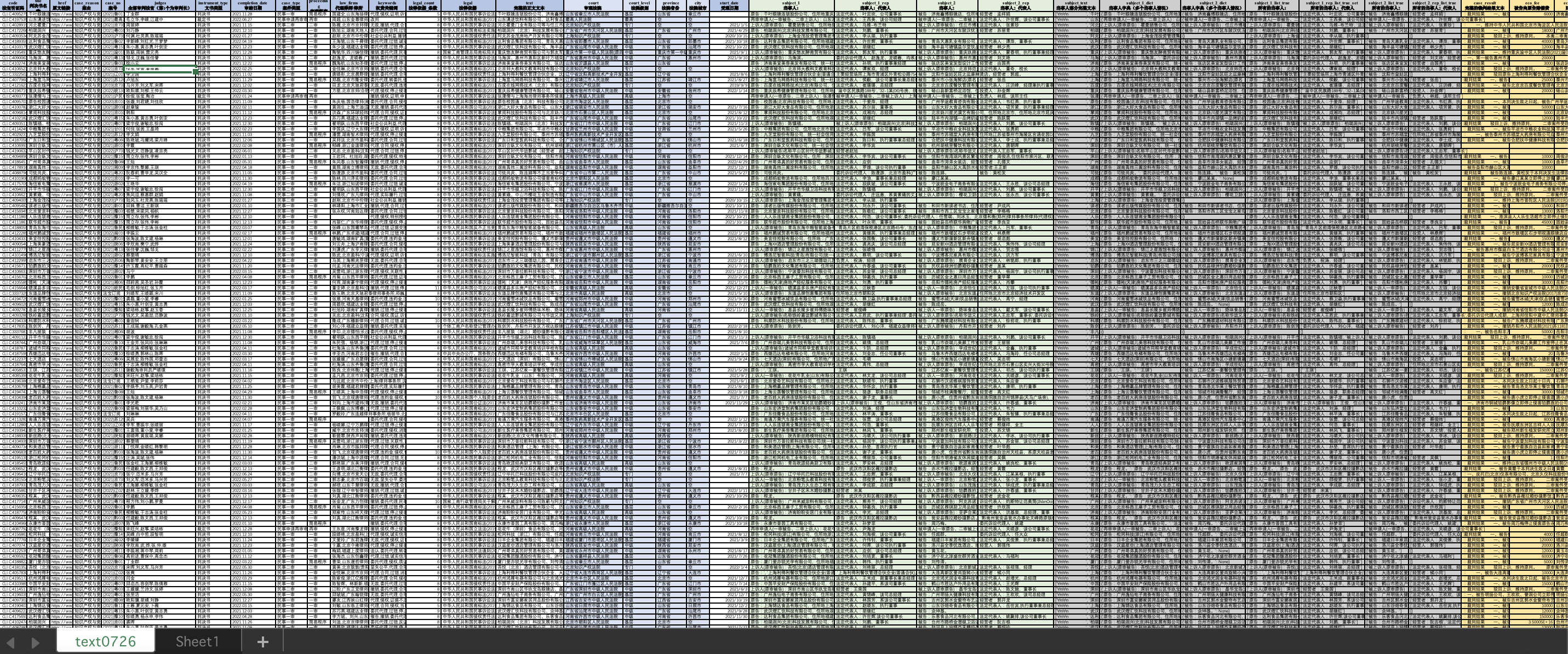
完整代码如下:
# -*- encoding:utf-8 -*-
import csv
import os
import re
from lxml import etree
from itertools import zip_longest
# ————————————————————————————————
# 文件保存
def save(film_content):
with open('../content/text17.csv', 'a+', newline='', encoding='gb18030') as f:
writer = csv.writer(f)
writer.writerow(film_content)
print('保存文件成功')
# 循环遍历本地文件夹中的HTML
def get_html():
path = 'all_html'
all_html = os.listdir(path)
os.chdir(path)
return all_html
# 逐行遍历TXT文件中的URL链接
# def open_txt():
# with open("url.txt", "r", encoding="utf-8")as f:
# for line in f.readlines():
# url_list.append(line.replace('\n', ''))
# url_list = []
items = []
num_select = 10
all_html = get_html()
# ————————————————————————————————
# 循环遍历
for num_text, html in enumerate(all_html):
# 定义所有用到的字段
title = ''
case_reason = ''
case_no = ''
judges = ''
judges_first = ''
instrument_type = ''
court = ''
completion_date = ''
case_type = ''
proceeding = ''
law_firms = ''
keywords = ''
court_level = ''
province = ''
subject_1 = ''
subject_2 = ''
subject_1_rep = ''
subject_2_rep = ''
legal_count = ''
legal = ''
subject_1_list_true = []
subject_1_rep_list_true = []
subject_2_list_true = []
subject_2_rep_list_true = []
city = ''
word = ''
start_date = ''
eco_fee = ''
eco_fee_yuangao = ''
eco_fee_beigao = ''
# 完整的正文文本 text
text = e.xpath("//div[@class='fulltext']//text()")
text = " ".join(text).strip()
# 法宝引证码code
code = e.xpath("//div[@class='logo']/div/text()")
code = "".join(code)
# 判决书名称title
title = e.xpath("//div/h2/text()")
title = "".join(title).strip()
# 原文链接 href
url = e.xpath("//div[@class='link']/a/@href")
url = "".join(url)
# 案由 case_reason
case_reason = e.xpath("//div[@class='fields']/ul/li[@class='row'][1]/div[@class='box']/a/text()")
case_reason = "".join(case_reason)
# 案号 case_no
try:
case_no = e.xpath("//div[@class='fields']/ul[1]//li//@title")[1]
except:
continue
# 落款中的审判长 judge_first
if ("二〇") in text:
obj_9 = re.compile("(?<=判决如下)(.+?)(?=二〇)", re.S).findall(text)
else:
obj_9 = re.compile("(?<=判决如下)(.+?)(?=二○)", re.S).findall(text)
if("审 判 长" ) in str(obj_9):
if("人民陪审员" ) in str(obj_9):
obj_10 = re.compile(r"(?<=审 判 长)(.+?)(?=人民陪审员)", re.S).findall(str(obj_9))
judges_first = ''.join(obj_10).replace("\\u3000", '').replace(' ', '').replace("<>style=\"font-family:仿宋;font-size:15pt;-aw-import:spaces\">",'')
else:
obj_10 = re.compile(r"(?<=审 判 长)(.+?)(?=审 判 员)", re.S).findall(str(obj_9))
judges_first = ''.join(obj_10).replace("\\u3000", '').replace(' ', '').replace("<>style=\"font-family:仿宋;font-size:15pt;-aw-import:spaces\">",'')
elif("审判长" ) in str(obj_9):
if ("人民陪审员") in str(obj_9):
obj_10 = re.compile(r"(?<=审判长)(.+?)(?=人民陪审员)", re.S).findall(str(obj_9))
judges_first = ''.join(obj_10).replace("\\u3000", '').replace(' ', '').replace("<>style=\"font-family:仿宋;font-size:15pt;-aw-import:spaces\">", '')
else:
obj_10 = re.compile(r"(?<=审判长)(.+?)(?=审判员)", re.S).findall(str(obj_9))
judges_first = ''.join(obj_10).replace("\\u3000", '').replace(' ', '').replace("<>style=\"font-family:仿宋;font-size:15pt;-aw-import:spaces\">",'')
elif("审 判 长" or "审判长") not in str(obj_9):
if("审判员") in str(obj_9):
obj_10 = re.compile(r"(?<=审判员 )(.+?)(?= '\])", re.S).findall(str(obj_9))
judges_first = ''.join(obj_10).replace("\\u3000", '').replace(' ', '').replace("<>style=\"font-family:仿宋;font-size:15pt;-aw-import:spaces\">", '')
elif("审 判 员") in str(obj_9):
obj_10 = re.compile(r"(?<=审 判 员 )(.+?)(?= '\])", re.S).findall(str(obj_9))
judges_first = ''.join(obj_10).replace("\\u3000", '').replace(' ', '').replace("<>style=\"font-family:仿宋;font-size:15pt;-aw-import:spaces\">", '')
# 受理日期 start_date
obj11 = re.compile(r"(?<=本院于)(.+?)(?=后)", re.S)
obj111 = str(obj11.findall(text))
obj12 = re.compile(r"\d{4}年\d{1,2}月\d{1,2}日",re.S)
start_date_list = obj12.findall(obj111)
if start_date_list:
start_date = start_date_list[0]
# 解析HTML页面:当事人+法律依据相关字段
e = etree.parse(html, etree.HTMLParser())
if e.xpath("//div[@class='fields']/ul//li[1]//text()"):
# 法律依据legal,法律依据条数legal_count
legal = e.xpath("//div[@class='correlation-info'][1]/ul/li/a/text()")
legal = "".join(legal).replace('\r\n', '').replace('侵权责任法 ', '侵权责任法').replace(') ', ')').split()
legal_count = len(legal)
legal = ";".join(legal)
# 当事人,当事人完整字段word
text = e.xpath('//div[@id="divFullText"]//text()')
wor = str(text)
word = wor.split('审理经过')[0].strip()
word = str(word)
# 辅助变量
subject_1_list = []
subject_1_rep_list = []
subject_2_list = []
subject_2_rep_list = []
# 根据关键词正则提取当事人1、当事人2的信息
if ('再审申请人' in word):
obj1 = re.compile(r"再审申请人(.+?)(?=',)", re.S)
subject_1_list = obj1.findall(word)
if subject_1_list:
for i in range(0,len(subject_1_list)):
subject_1_list_true.append('再审申请人' + str(subject_1_list[i]))
subject_1 = subject_1_list_true[0]
obj66 = re.compile(r"再审申请人.*?,(.*?)。", re.S)
subject_1_rep_list= obj66.findall(word)
if subject_1_rep_list:
for i in range(0, len(subject_1_rep_list)):
subject_1_rep_list_true.append(subject_1_rep_list[i].replace(" \'\\u3000\\u3000", ''))
subject_1_rep = str(subject_1_rep_list_true[0])
obj2 = re.compile(r"被申请人(.+?)(?=',)", re.S)
subject_2_list = obj2.findall(word)
if subject_2_list:
for i in range(0,len(subject_2_list)):
subject_2_list_true.append('被申请人' + str(subject_2_list[i]))
subject_2 = subject_2_list_true[0]
obj65 = re.compile(r"被申请人.*?,(.*?)。", re.S)
subject_2_rep_list = obj65.findall(word)
if subject_2_rep_list:
for i in range(0, len(subject_2_rep_list)):
subject_2_rep_list_true.append(subject_2_rep_list[i].replace(" \'\\u3000\\u3000", ''))
subject_2_rep = str(subject_2_rep_list_true[0])
elif ('上诉人' in word):
obj1 = re.compile(r"3000上诉人\((.+?)(?=', ')", re.S)
subject_1_list = obj1.findall(word)
if subject_1_list:
for i in range(0,len(subject_1_list)):
subject_1_list_true.append('上诉人(' + subject_1_list[i])
subject_1 = subject_1_list_true[0]
obj66 = re.compile(r"3000上诉人\(.*?,(.*?)。", re.S)
subject_1_rep_list= obj66.findall(word)
# print(subject_1_rep_list)
if subject_1_rep_list:
for i in range(0, len(subject_1_rep_list)):
subject_1_rep_list_true.append(subject_1_rep_list[i].replace(" \'\\u3000\\u3000", ''))
subject_1_rep = str(subject_1_rep_list_true[0])
obj2 = re.compile(r"\\u3000被上诉人\((.+?)(?=',)", re.S)
subject_2_list = obj2.findall(word)
if subject_2_list:
for i in range(0, len(subject_2_list)):
subject_2_list_true.append('被上诉人' + subject_2_list[i])
subject_2 = subject_2_list_true[0]
obj65 = re.compile(r"被上诉人\(.*?,(.*?)。", re.S)
subject_2_rep_list = obj65.findall(word)
# print(subject_2_rep_list)
if subject_2_rep_list:
for i in range(0, len(subject_2_rep_list)):
subject_2_rep_list_true.append(subject_2_rep_list[i].replace(" \'\\u3000\\u3000", ''))
subject_2_rep = str(subject_2_rep_list_true[0])
elif ('原告:' in word):
obj1 = re.compile(r"原告:(.+?)(?=',)", re.S)
subject_1_list = obj1.findall(word)
if subject_1_list:
for i in range(0, len(subject_1_list)):
subject_1_list_true.append('原告:' + str(subject_1_list[i]))
subject_1 = subject_1_list_true[0]
obj66 = re.compile(r"原告:.*?,(.*?)。", re.S)
# print(word)
subject_1_rep_list = obj66.findall(word)
# print(subject_1_rep_list)
if subject_1_rep_list:
for i in range(0, len(subject_1_rep_list)):
subject_1_rep_list_true.append(subject_1_rep_list[i].replace(" \'\\u3000\\u3000", ''))
subject_1_rep = str(subject_1_rep_list_true[0])
obj2 = re.compile(r"被告:(.+?)(?=',)", re.S)
subject_2_list = obj2.findall(word)
if subject_2_list:
for i in range(0, len(subject_2_list)):
subject_2_list_true.append('被告:' + str(subject_2_list[i]))
subject_2 = subject_2_list_true[0]
obj65 = re.compile(r"被告:.*?,(.*?)。", re.S)
subject_2_rep_list = obj65.findall(word)
print(subject_2_rep_list)
if subject_2_rep_list:
for i in range(0, len(subject_2_rep_list)):
subject_2_rep_list_true.append(subject_2_rep_list[i].replace(" \'\\u3000\\u3000", ''))
subject_2_rep = str(subject_2_rep_list_true[0])
# 当事人1列表去重复
subject_1_rep_list_true_set = sorted(set(subject_1_rep_list_true), key=subject_1_rep_list_true.index)
# 使用zip将两个当事人list合并成dict
subject_1_dict = dict(zip_longest(subject_1_list_true, subject_1_rep_list_true_set))
subject_2_dict = dict(zip_longest(subject_2_list_true, subject_2_rep_list_true))
# 辅助打印测试当事人情况
# print("-------------------")
# print(subject_1_dict)
# print(subject_2_dict)
# print("subject_1"+ subject_1)
# print("subject_1_list:",str(subject_1_list_true))
# print("subject_1_rep"+ subject_1_rep)
# print("subject_1_rep_list",subject_1_rep_list_true_set)
# print("subject_2"+ subject_2)
# print("subject_2_list",subject_2_list_true)
# print("subject_2_rep"+subject_2_rep)
# print("subject_2_rep_list",subject_2_rep_list_true)
# 完整判决结果文本
if ('落款' in wor):
obj4 = re.compile("判决如下(.*?)落款", re.S)
result_1 = obj4.findall("".join(text))
else:
obj4 = re.compile("判决如下(.*?)二〇", re.S)
result_1 = obj4.findall("".join(text))
case_result = ''.join(result_1).replace("'", "").replace("\\u3000", "").replace(',', '').strip()
# 经济赔偿损失,原告与被告负担情况
obj_1 = re.compile(r"(?<=[一|二|三|四|五|六|七|八|九|十]、)(?=被告)(.+?)(?=[于本判决|应于本判决])", re.S).findall(case_result)
if obj_1:
eco_fee_beigao =''.join(str(obj_1[0])).replace("被告", '')
obj_2 = re.compile(r"(?<=赔偿原告)(.+?)(?=经济损失)",re.S).findall(case_result)
eco_fee_yuangao=''.join(obj_2)
obj_3 = re.compile(r"(?<=十日内赔偿原告)(.+?)(?=元)",re.S).findall(case_result)
obj_4 = re.compile(r"\d+\.?\d*", re.S).findall(str(obj_3))
eco_fee =''.join(obj_4)
# #受理费及负担情况(待完成)
# if("二审" in case_result):
# if("一审" in case_result):
# obj_5 = re.compile(r"(?<=[一审案件受理费|一审受理费])(.+?)(?=元)", re.S).findall(case_result)
# obj_6 = re.compile(r"\d+\.?\d*", re.S).findall(str(obj_3))
# shouli_1_fee = ''.join(obj_6)
# 方框中的基本信息
try:
for i in range(2, 12):
contant = e.xpath(f"//div[@class='fields']/ul//li[{i}]//text()")
data = "".join(contant).split()[0]
if data == '审理法官:':
judges = "".join(contant).split()[1::]
judges = ",".join(judges)
elif data == '文书类型:':
instrument_type = "".join(contant).split()[1]
elif data == '审理法院:':
court = "".join(contant).split()[1]
# 提取法院的基本信息,court_level 法院级别;province 法院省份; city 法院城市
try:
if ("最高" in court):
court_level = '最高'
province = '空'
city = '空'
elif ("高级" in court):
court_level = '高级'
if ("省" in court):
province = court.split('省')[0] + '省'
if ("市" in court):
city = court.split("省")[1].split('市')[0] + '市'
else:
city = '空'
elif ("自治州" in court):
province = court.split('自治州')[0] + '自治州'
if ("市" in court):
city = court.split("自治州")[1].split('市')[0] + '市'
elif ("市" in court):
province = court.split('市')[0] + '市'
city = '空'
else:
city = '空'
province = '空'
elif ("中级" in court):
court_level = '中级'
if ("省" in court):
province = court.split('省')[0] + '省'
if ("市" in court):
city = court.split("省")[1].split('市')[0] + '市'
elif ("自治州" in court):
province = court.split('自治州')[0] + '自治州'
if ("市" in court):
city = court.split("自治州")[1].split('市')[0] + '市'
elif ("市" in court):
province = court.split('市')[0] + '市'
city = '空'
else:
city = '空'
province = '空'
elif ("知识产权" in court):
court_level = '专门'
city = '空'
province = '空'
elif ("区" or "县" in court):
court_level = '基层'
if ("省" in court):
province = court.split('省')[0] + '省'
if ("市" in court):
city = court.split("省")[1].split('市')[0] + '市'
elif ("自治州" in court):
province = court.split('自治州')[0] + '自治州'
if ("市" in court):
city = court.split("自治州")[1].split('市')[0] + '市'
elif ("市" in court):
province = court.split('市')[0] + '市'
city = '空'
else:
city = '空'
province = '空'
else:
court_level = ''
city = '空'
province = '空'
except:
pass
elif data[0:5:] == '审结日期:':
completion_date = data[5::]
elif data == '案件类型:':
case_type = "".join(contant).split()[1]
elif data == '审理程序:':
proceeding = "".join(contant).split()[1]
elif data == '代理律师/律所:':
law_firms = "".join(contant).split()[1::]
law_firms = ",".join(law_firms).replace(',,', '').replace(',;', '')
elif data == '权责关键词:':
keywords = "".join(contant).split()[1::]
keywords = ",".join(keywords)
# 保存字段
item = [code, title, url, case_reason, case_no, judges, judges_first,instrument_type,completion_date, case_type,proceeding, law_firms, keywords,legal_count, legal,text,
court, court_level, province, city,start_date,
subject_1, subject_1_rep, subject_2, subject_2_rep,
word, subject_1_dict, subject_2_dict, subject_1_list_true, subject_1_rep_list_true_set,subject_2_list_true, subject_2_rep_list_true,
case_result,eco_fee,eco_fee_beigao,eco_fee_yuangao]
print(f"第{num_text + 1}个爬取成功,titile是{title}")
save(item)
except:
item = [code, title, url, case_reason, case_no, judges, judges_first,instrument_type,completion_date, case_type,proceeding, law_firms, keywords,legal_count, legal,text,
court, court_level, province, city,start_date,
subject_1, subject_1_rep, subject_2, subject_2_rep,
word, subject_1_dict, subject_2_dict, subject_1_list_true, subject_1_rep_list_true_set,subject_2_list_true, subject_2_rep_list_true,
case_result,eco_fee,eco_fee_beigao,eco_fee_yuangao]
print(f"第{num_text + 1}个爬取成功,titile是{title}")
save(item)
pass
总结
本次项目看着需求简单,但过程却花费了很多时间,特别是正则过程中的条件判断很麻烦,需要找到并总结多种情况的规律再去编程,但好歹初步解决了问题。
针对此次项目接下来还需做的:
1、当事人相关字段基本都提取出来,但有一些情况仍然没有覆盖到,这些特例需要人工修改(其中标注灰色的变量是后面修改可能用到的数据);
2、金额相关的经济赔偿费和受理费,情况太多,仍然需要完善;
3、ToB、ToC等字段规则确定后,仍需编程实现;
4、等待北大法宝的经理给予反馈,如果可以直接下载4000多HTML,拿到后只需要跑一遍程序即可;如果不行就需要花时间手动下载;
5、代码效率仍然不高,有空需要提高;